






















































Dealing with out-of-date models
So, you've trained the perfect model and the data is flowing into the algorithm with great results. Sit back and just relax, right? Well, not quite. Just like you constantly need to adjust a menu at a restaurant to keep up with new customers' preferences, you will need to update your model to take in new data and adapt accordingly. Thankfully, you have quite a few tools at your disposal to do so.
In addition to the nature of the training data being used to classify types of AI model algorithms, how or when the training happensis also taken into consideration. Let's look at the two types of training methods in more detail: online versus batch.
Difference between online and batch learning
Online learning is the process where you have a live learning process that can take in new data as it comes in to adjust the algorithm. Think of learning how to play golf for the first time. At the beginning, you have watched just a bit of the PGA tour, and you know that you need to grab a club and swing away. You pick a club at random and start hacking. After a few sand traps and quadruple bogeys, you have a friend who gives you some pointers, and you realize that after adjusting, you have managed to cut your strokes down a lot by the last 9 holes. You've adjusted your game on the fly.
Making sure you didn't just take a static approach to what you were doing allows you to tweak your approach and incorporate the new info into what you were doing.
The other approach is batch learning. Batch learning is when you take a chunk of data and feed it into the training stage to spit out a static model. Going back to our earlier example in our quest to get our tour card, this would be like after playing your 18 holes, you went to take some lessons from a pro, and then went back out onto the course to test out your new approach.
This is where one of the key misconceptions arises with ML. AI models don't simply improve on their own as they take in and process data from the world. There are ways to do that, and many of the AI models deployed use the batch learning process.
Why not use online learning all the time? Well, is getting a friend to help you on the golf course better than taking the time to talk to a professional? There are pros and cons to each. Let's go over a few of these now:
- The first reason is the business scenario at hand. For example, if you are trying to make predictions on the outcome of a sporting event before it happens, it makes no sense to use online learning.
- Another is that setting up batch learning allows you to parse out and have more control over the exact data that is fed into your model. You can create a data pipeline that applies certain rules to the data flowing in, but you still won't be able to put the same care and analysis into the data as it goes into a batch process.
- The next reason is convenience. Sometimes, the data is far away from where your model inference is happening. Inference is when your model is actually processing the live data through the system, many times referred to simply as running or scoring the model. Maybe you are running your model on an edge device such as a phone or IoT device. In that case, there might not be a simple or efficient way to get mountains of data processed and into the right place to train.
- Training is also costly in terms of both time and money, and this relates back to the location of where this model is running. Many types of models need a beefy GPU, CPU, memory, or some other dedicated hardware that isn't in place. Separating your training from where your model runs lets you separate these phases and allows you to have specialized devices or architecture designed around the exact use case. For example, maybe training your model requires GPUs that you rent for $5,000 an hour, but once your model is trained, it can be used on a $50 machine.
- The last reason for not using online learning is simply that you don't want the deployed model to change. If you have a self-driving car, do you really want new data to be taken in, causing each of your cars to have a slightly different model? This would result in 100,000+ different models running at a time in the wild. Each one could almost be guaranteed to have slightly different innards than the original source of truth. The implications from a moral and safety perspective are massive, not to mention trying to QA what is going on and why. In this scenario, it's much better to have a golden standard that you can train, and then test. That way, when you roll out an update such as Tesla does (and no doubt others will have followed by the time you read this), that exact model has already been tested by running in the real world.
On the other hand, online learning does have a massive advantage in the areas where you have the ability and support to grab new data coming in. An example of when you might want to do this is predictive analytics, which is when you use historical data to predict things such as when a wind turbine might fail. Being able to train on live data could help you when the weather starts to change, and the operational mechanics of a physical system might operate differently. Fast forward weeks or months into the future, and you might have a much better result than a static model.
Online learning helps a great deal with model drift, which we will cover in the next section.
How models become stale: model drift
Drift is a major problem in the ML world. What is drift? Model drift is when the data you trained the model on doesn't represent the current state of the world in which the model is deployed. The Netflix algorithm trained on your preferences might be off after your sibling watches all the shows they like. A wind turbine operation was fed temperatures and conditions for the summer, but now winter storms have dramatically changed the climate it operates in.
Coming back to our golfing example, this would be like getting fantastic at a single course, but then the course owners decided to mix things up, moving all the bunkers to drift to where your favorite tee shot on hole 4 was. If you don't take into account this new drift, you'll find yourself eating sand instead of smugly walking up to your perfectly placed tee shot.
Let's take a look at this golf example to see how things can change from what you expect from one week to the next. In the first diagram, you see your normal golf shot, while in the second, you can see that same shot the following week, after that bunker location has changed:
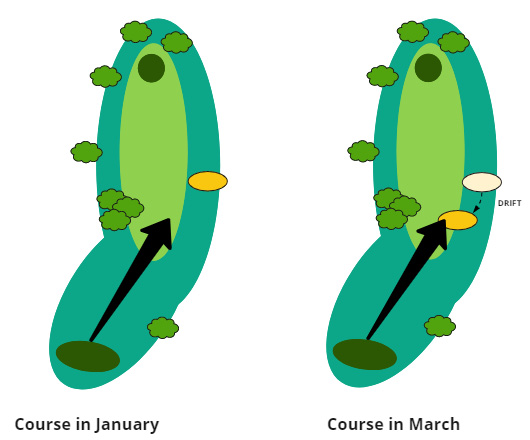
Figure 1.6 – Golf course showcasing the model drift of a bunker
As you can see in the second diagram, the course designer decided to move the bunker closer to the tee box. You could continue to hit your shot in the same position as before, but you would get much worse results after this change as you are now hitting straight into this sand trap. This is what you need to do with your models; make sure you are paying attention and realize that we live in a dynamic world that can evolve.
Model drift is an important concept to consider, and there are many tools that can help with this, which we'll look at further in Chapter 8, Dealing with Common Data Problems. But now let's look at how you would even install these tools in the first place.


