






















































Cloud-native approach to implementing DevOps using Google Cloud
This section elaborates on how to implement DevOps using Google Cloud services with a focus on a cloud-native approach – an approach that uses cloud computing at its core to build highly available, scalable, and resilient applications.
Focus on microservices
A monolith application has a tightly coupled architecture and implements all possible features in a single code base along with the database. Though monolith applications can be designed with modular components, the components are still packaged at deployment time and deployed together as a single unit. From a CI/CD standpoint, this will potentially result in a single build pipeline. Fixing an issue or adding a new feature is an extremely time-consuming process since the impact is on the entire application. This decreases the release velocity and essentially is a nightmare for production support teams dealing with service disruption.
In contrast, a microservice application is based on service-oriented architecture. A microservice application divides a large program into several smaller, independent services. This allows the components to be managed by smaller teams as the components are more isolated in nature. The teams, as well as the service, can be independently scaled. Microservices fundamentally support the concept of incremental code change. With microservices, the individual components are deployable. Given that microservices are feature-specific, in the event of an issue, fault detection and isolation are much easier and hence service disruptions can be handled quickly and efficiently. This also makes it much more suitable for CI/CD processes and works well with the theme of building reliable software faster!
Exam tip
Google Cloud provides several compute services that facilitate the deployment of microservices as containers. These include App Engine flexible environment, Cloud Run, Google Compute Engine (GCE), and Google Kubernetes Engine (GKE). From a Google Cloud DevOps exam perspective, the common theme is to build containers and deploy containers using GKE. GKE will be a major focus area and will be discussed in detail in the upcoming chapters.
Cloud-native development
Google promotes and recommends application development using the following cloud-native principles:
- Use microservice architectural patterns: As discussed in the previous sub-section, the essence is to build smaller independent services that could be managed separately and be scaled granularly.
- Treat everything as code: This principle makes it easier to track, roll back code if required, and see the version of change. This includes source code, test code, automation code, and infrastructure as code.
- Build everything as containers: A container image can include software dependencies needed by the application, specific language runtimes, and other software libraries. Containers can be run anywhere, making it easier to develop and deploy. This allows developers to focus on code and ops teams will spend less time debugging and diagnosing differences in environments.
- Design for automation: Automated processes can repair, scale, and deploy systems faster than humans. As a critical first step, a comprehensive CI/CD pipeline is required that can automate the build, testing, and deployment process. In addition, the services that are deployed as containers should be configured to scale up or down based on outstanding traffic. Real-time monitoring and logging should be used as a source for automation since they provide insights into potential issues that could be mitigated by building proactive actions. The idea of automation can also be extended to automate the entire infrastructure using techniques such as Infrastructure as Code (IaC).
- Design components to be stateless wherever possible: Stateless components are easy to scale up or down, repair a failed instance by graceful termination and potential replacement, roll back to an older instance in case of issues, and make load balancing a lot simpler since any instance can handle any request. Any need to store persistent data should happen outside the container, such as storing files using Cloud Storage, storing user sessions through Redis or Memcached, or using persistent disks for block-level storage.
Google Cloud provides two approaches for cloud-native development – serverless and Kubernetes. The choice comes down to focus on infrastructure versus business logic:
- Serverless (via Cloud Run, Cloud Functions, or App Engine): Allows us to focus on the business logic of the application by providing a higher level of abstraction from an infrastructure standpoint.
- Kubernetes (via GKE): Provides higher granularity and control on how multiple microservices can be deployed, how services can communicate with each other, and how external clients can interact with these services.
Managed versus serverless service
Managed services allow operations related to updates, networking, patching, high availability, automated backups, and redundancy to be managed by the cloud provider. Managed services are not serverless as it is required to specify a machine size and the service mandates to have a minimal number of VMs/nodes. For example, it is required to define the machine size while creating a cloud SQL instance, but updates and patches can be configured to be managed by Google Cloud.
Serverless services are managed but do not require reserving a server upfront or keeping it running. The focus is on the business logic of the application with the possibility of running or executing code only when needed. Examples are Cloud Run, Cloud Storage, Cloud Firestore, and Cloud Datastore.
Continuous integration in GCP
Continuous integration forms the CI of the CI/CD process and at its heart is the culture of submitting smaller units of change frequently. Smaller changes minimize the risk, help to resolve issues quickly, increase development velocity, and provide frequent feedback. The following are the building blocks that make up the CI process:
- Make code changes: By using the IDE of choice and possible cloud-native plugins
- Manage source code: By using a single shared code repository
- Build and create artifacts: By using an automated build process
- Store artifacts: By storing artifacts such as container images in a repository for a future deployment process
Google Cloud has an appropriate service for each of the building blocks that allows us to build a GCP-native CI pipeline (refer to Figure 1.2). The following is a summary of these services, which will be discussed in detail in upcoming chapters:
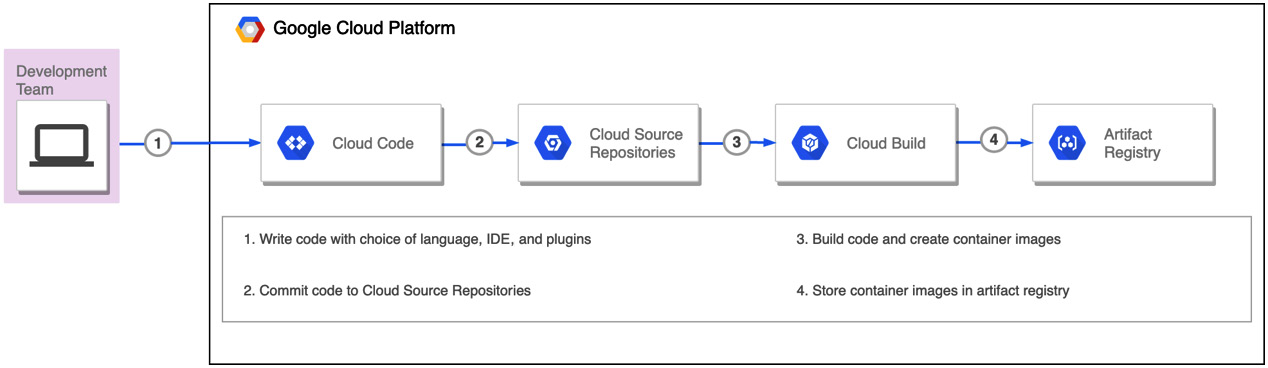
Figure 1.2 – CI in GCP
Let's look at these stages in detail.
Cloud Code
This is the GCP service to write, debug, and deploy cloud-native applications. Cloud Code provides extensions to IDEs such as Visual Studio Code and the JetBrains suite of IDEs that allows to rapidly iterate, debug, and run code on Kubernetes and Cloud Run. Key features include the following:
- Speed up development and simplify local development
- Extend to production deployments on GKE or Cloud Run and allow debugging deployed applications
- Deep integration with Cloud Source Repositories and Cloud Build
- Easy to add and configure Google Cloud APIs from built-in library manager
Cloud Source Repositories
This is the GCP service to manage source code. It provides Git version control to support the collaborative development of any application or service. Key features include the following:
- Fully managed private Git repository
- Provides one-way sync with Bitbucket and GitHub source repositories
- Integration with GCP services such as Cloud Build and Cloud Operations
- Includes universal code search within and across repositories
Cloud Build
This is the GCP service to build and create artifacts based on commits made to source code repositories such as GitHub, Bitbucket, or Google's Cloud Source Repositories. These artifacts can be container or non-container artifacts. The GCP DevOps exam's primary focus will be on container artifacts. Key features include the following:
- Fully serverless platform with no need to pre-provision servers or pay in advance for additional capacity. Will scale up and down based on load
- Includes Google and community builder images with support for multiple languages and tools
- Includes custom build steps and pre-created extensions to third-party apps that enterprises can easily integrate into their build process
- Focus on security with vulnerability scanning and the ability to define policies that can block the deployment of vulnerable images
Container/Artifact Registry
This is the GCP construct to store artifacts that include both container (Docker images) and non-container artifacts (such as Java and Node.js packages). Key features include the following:
- Seamless integration with Cloud Source Repositories and Cloud Build to upload artifacts to Container/Artifact Registry.
- Ability to set up a secure private build artifact storage on Google Cloud with granular access control.
- Create multiple regional repositories within a single Google Cloud project.
Continuous delivery/deployment in GCP
Continuous delivery/deployment forms the CD of the CI/CD process and at its heart is the culture of continuously delivering production-ready code or deploying code to production. This allows us to release software at high velocity without sacrificing quality.
GCP offers multiple services to deploy code, such as Compute Engine, App Engine, Kubernetes Engine, Cloud Functions, and Cloud Run. The focus of this book will be on GKE and Cloud Run. This is in alignment with the Google Cloud DevOps exam objectives.
The following figure summarizes the different stages of continuous delivery/deployment from the viewpoint of appropriate GCP services:

Figure 1.3 – Continuous delivery/deployment in GCP
Let's look at the two container-based deployments in detail.
Google Kubernetes Engine (GKE)
This is the GCP service to deploy containers. GKE is Google Cloud's implementation of the CNCF Kubernetes project. It's a managed environment for deploying, managing, and scaling containerized applications using Google's infrastructure. Key features include the following:
- Automatically provisions and manages a cluster's master-related infrastructure and abstracts away the need for a separate master node
- Automatic scaling of a cluster's node instance count
- Automatic upgrades of a cluster's node software
- Node auto-repair to maintain the node's health
- Native integration with Google's Cloud Operations for logging and monitoring
Cloud Run
This is a GCP-managed serverless platform that can deploy and run Docker containers. These containers can be deployed in either Google-managed Kubernetes clusters or on-premises workloads using Cloud Run for Anthos. Key features include the following:
- Abstracts away infrastructure management by automatically scaling up and down
- Only charges for exact resources consumed
- Native GCP integration with Google Cloud services such as Cloud Code, Cloud Source Repositories, Cloud Build, and Artifact Registry
- Supports event-based invocation via web requests with Google Cloud services such as Cloud Scheduler, Cloud Tasks, and Cloud Pub/Sub
Continuous monitoring/operations on GCP
Continuous Monitoring/Operations forms the feedback loop of the CI/CD process and at its heart is the culture of continuously monitoring or observing the performance of the service/application.
GCP offers a suite of services that provide different aspects of Continuous Monitoring/Operations, aptly named Cloud Operations (formerly known as Stackdriver). Cloud Operations includes Cloud Monitoring, Cloud Logging, Error Reporting, and Application Performance Management (APM). APM further includes Cloud Debugger, Cloud Trace, and Cloud Profiler. Refer to the following diagram:
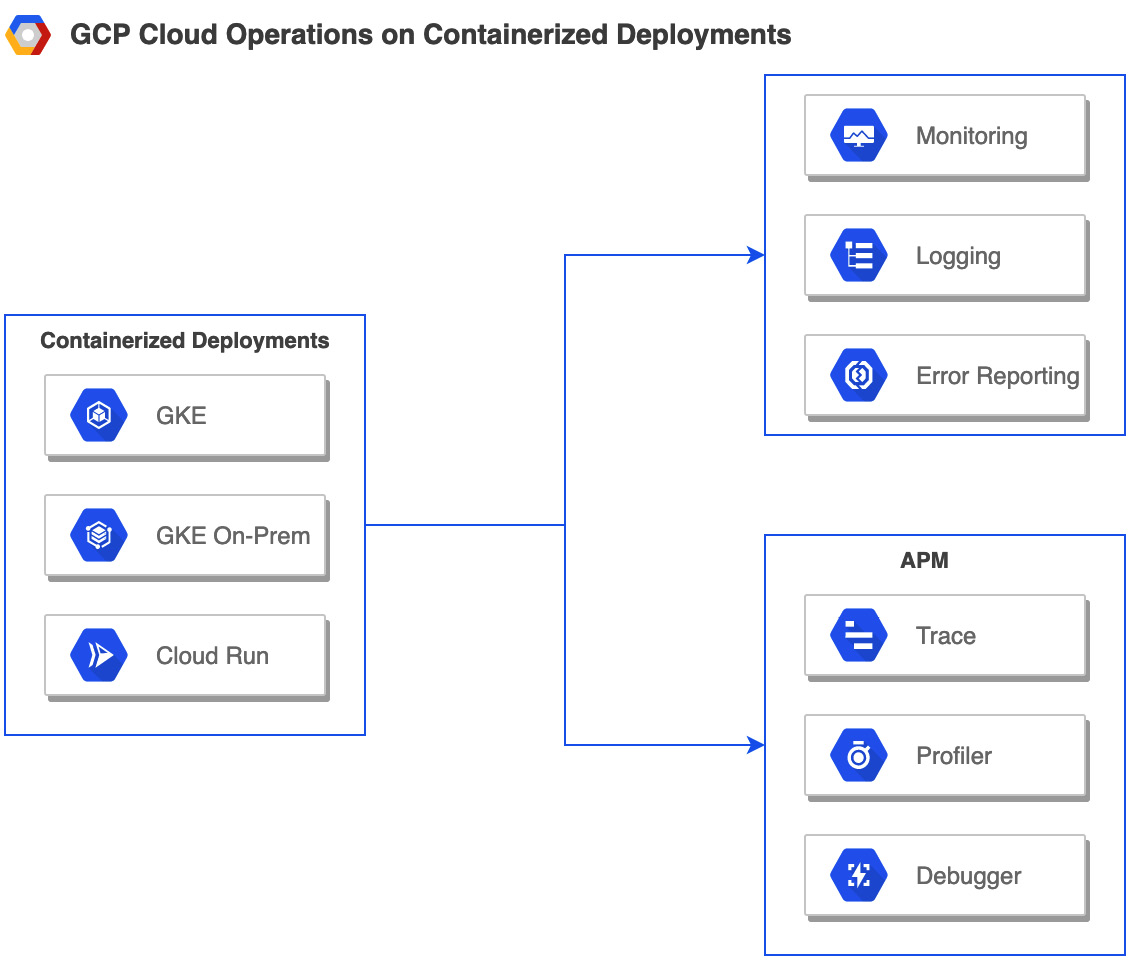
Figure 1.4 – Continuous monitoring/operations
Let's look at these operations- and monitoring-specific services in detail.
Cloud Monitoring
This is the GCP service that collects metrics, events, and metadata from Google Cloud and other providers. Key features include the following:
- Provides out-of-the-box default dashboards for many GCP services
- Supports uptime monitoring and alerting to various types of channels
- Provides easy navigation to drill down from alerts to dashboards to logs and traces to quickly identify the root cause
- Supports non-GCP environments with the use of agents
Cloud Logging
This is the GCP service that allows us to store, search, analyze, monitor, and alert on logging data and events from Google Cloud and Amazon Web Services. Key features include the following:
- A fully managed service that performs at scale with sub-second ingestion latency at terabytes per second
- Analyzes log data across multi-cloud environment from a single place
- Ability to ingest application and system log data from thousands of VMs
- Ability to create metrics from streaming logs and analyze log data in real time using BigQuery
Error Reporting
This is the GCP service that aggregates, counts, analyzes, and displays application errors produced from running cloud services. Key features include the following:
- Dedicated view of error details that include a time chart, occurrences, affected user count, first and last seen dates, and cleaned exception stack trace
- Lists out the top or new errors in a clear dashboard
- Constantly analyzes exceptions and aggregates them into meaningful groups
- Can translate the occurrence of an uncommon error into an alert for immediate attention
Application Performance Management
This is the GCP service that combines monitoring and troubleshooting capabilities of Cloud Logging and Cloud Monitoring with Cloud Trace, Cloud Debugger, and Cloud Profiler, to help reduce latency and cost and enable us to run applications more efficiently. Key features include the following:
- A distributed tracing system (via Cloud Trace) that collects latency data from your applications to identify performance bottleneck
- Inspects a production application by taking a snapshot of the application state in real time, without stopping or slowing down (via Cloud Debugger), and provides the ability to inject log messages as part of debugging
- Low-impact production profiling (via Cloud Profiler) using statistical techniques, to present the call hierarchy and resource consumption of relevant function in an interactive flame graph
Bringing it all together – building blocks for a CI/CD pipeline in GCP
The following figure represents the building blocks that are required to build a CI/CD pipeline in GCP:
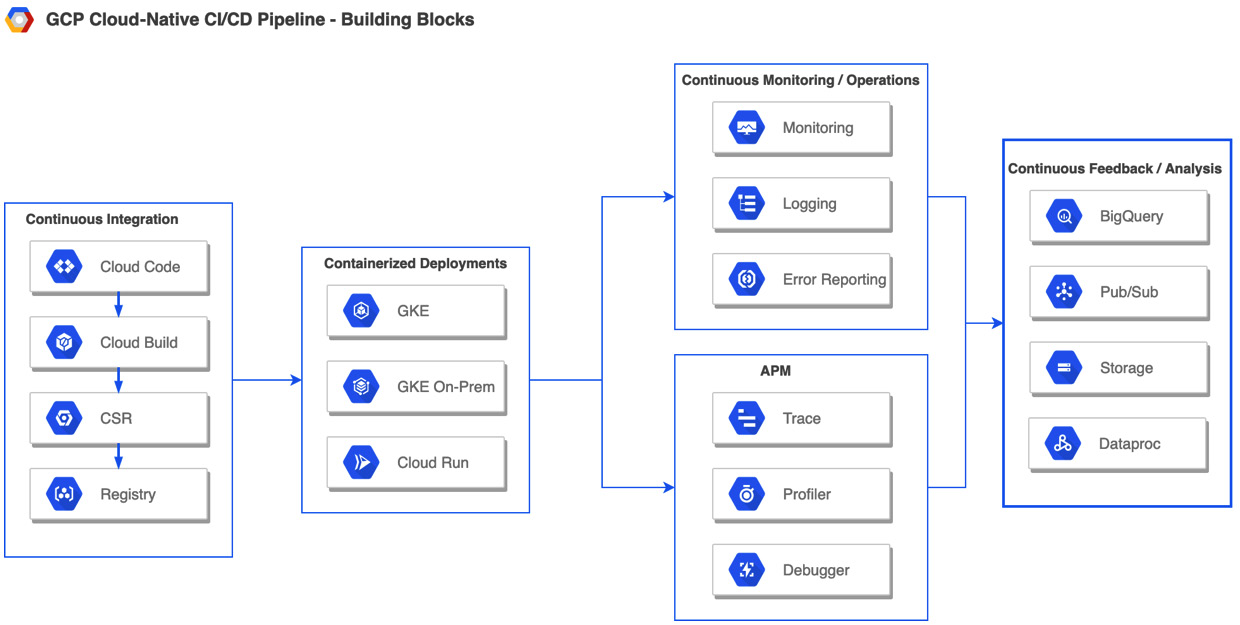
Figure 1.5 – GCP building blocks representing the DevOps life cycle
In the preceding figure, the section for Continuous Feedback/Analysis represents the GCP services that are used to analyze or store information obtained during Continuous Monitoring/Operations either from an event-driven or compliance perspective. This completes the section on an overview of Google Cloud services that can be used to implement the key stages of the DevOps life cycle using a cloud-native approach with emphasis on decomposing a complex system into microservices that can be independently tested and deployed.






