






















































Reading data from URLs
Files can be downloaded and stored locally on your machine, or stored on a remote server or cloud location. In the earlier two recipes, Reading from CSVs and other delimited files, and Reading data from an Excel file, both files were stored locally.
Many of the pandas reader functions can read data from remote locations by passing a URL path. For example, both read_csv() and read_excel() can take a URL to read a file that is accessible via the internet. In this recipe, you will read a CSV file using pandas.read_csv() and Excel files using pandas.read_excel() from remote locations, such as GitHub and AWS S3 (private and public buckets). You will also read data directly from an HTML page into a pandas DataFrame.
Getting ready
You will need to install the AWS SDK for Python (Boto3) for reading files from S3 buckets. Additionally, you will learn how to use the storage_options parameter available in many of the reader functions in pandas to read from S3 without the Boto3 library.
To use an S3 URL (for example, s3://bucket_name/path-to-file) in pandas, you will need to install the s3fs library. You will also need to install an HTML parser for when we use read_html(). For example, for the parsing engine (the HTML parser), you can install either lxml or html5lib; pandas will pick whichever is installed (it will first look for lxml, and if that fails, then for html5lib). If you plan to use html5lib you will need to install Beautiful Soup (beautifulsoup4).
To install using pip, you can use the following command:
>>> pip install boto3 s3fs lxml
To install using Conda, you can use:
>>> conda install boto3 s3fs lxml -y
How to do it…
This recipe will present you with different scenarios when reading data from online (remote) sources. Let's import pandas upfront since you will be using it throughout this recipe:
import pandas as pd
Reading data from GitHub
Sometimes, you may find useful public data on GitHub that you want to use and read directly (without downloading). One of the most common file formats on GitHub are CSV files. Let's start with the following steps:
- To read a CSV file from GitHub, you will need the URL to the raw content. If you copy the file's GitHub URL from the browser and use it as the file path, you will get a URL that looks like this: https://github.com/PacktPublishing/Time-Series-Analysis-with-Python-Cookbook./blob/main/datasets/Ch2/AirQualityUCI.csv. This URL is a pointer to the web page in GitHub and not the data itself; hence when using
pd.read_csv(), it will throw an error:url = 'https://github.com/PacktPublishing/Time-Series-Analysis-with-Python-Cookbook./blob/main/datasets/Ch2/AirQualityUCI.csv'
pd.read_csv(url)
ParserError: Error tokenizing data. C error: Expected 1 fields in line 62, saw 2
- Instead, you will need the raw content, which will give you a URL that looks like this: https://raw.githubusercontent.com/PacktPublishing/Time-Series-Analysis-with-Python-Cookbook./main/datasets/Ch2/AirQualityUCI.csv:
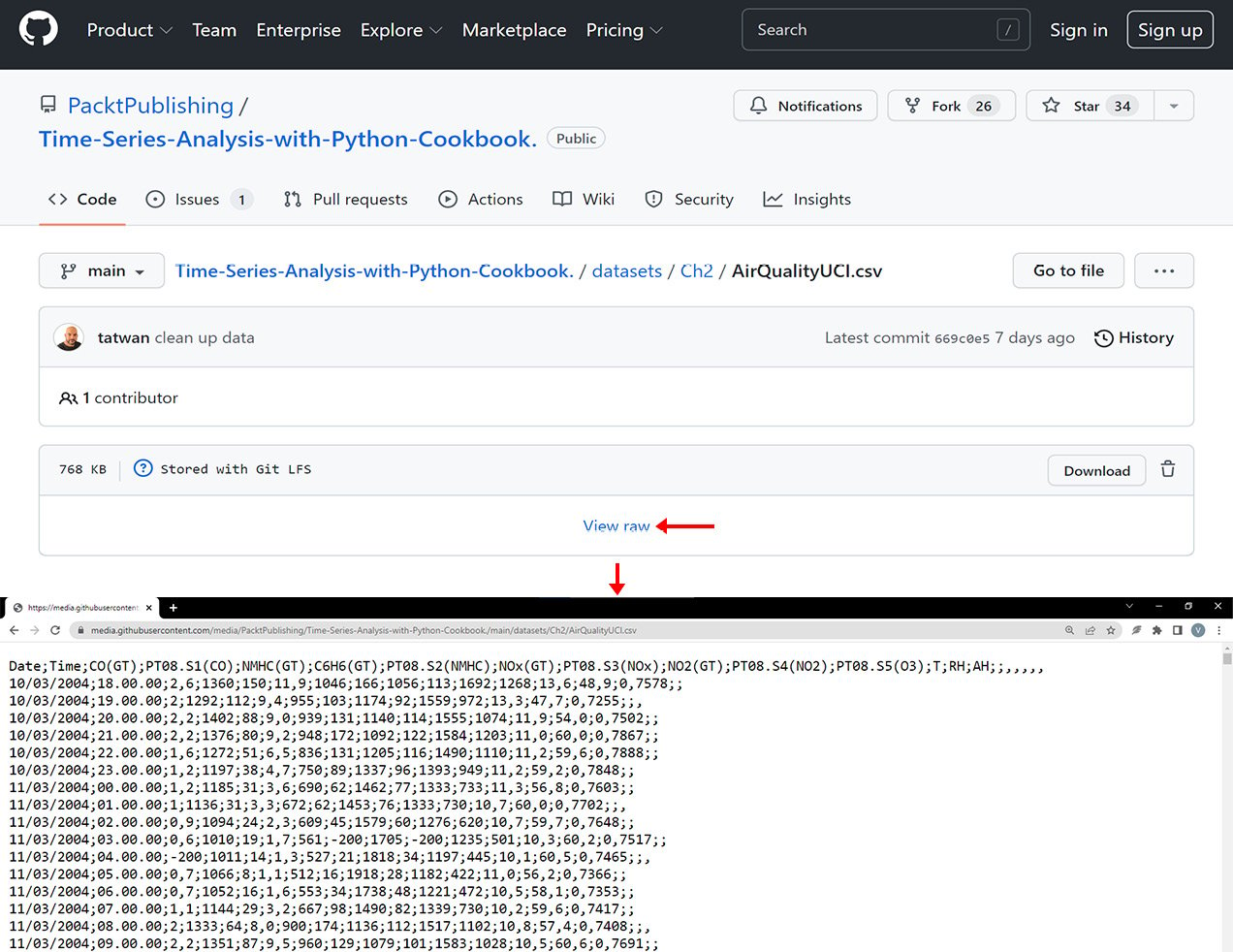
Figure 2.4 – The GitHub page for the CSV file. Note the View raw button
- In Figure 2.4, notice that the values are not comma-separated (not a comma-delimited file); instead, the file uses semicolon (
;) to separate the values.
The first column in the file is the Date column. You will need to parse (parse_date parameter) and convert it to DatetimeIndex (index_col parameter).
Pass the new URL to pandas.read_csv():
url = 'https://media.githubusercontent.com/media/PacktPublishing/Time-Series-Analysis-with-Python-Cookbook./main/datasets/Ch2/AirQualityUCI.csv' date_parser = lambda x: pd.to_datetime(x, format="%d/%m/%Y") df = pd.read_csv(url, delimiter=';', index_col='Date', date_parser=date_parser) df.iloc[:3,1:4] >> CO(GT) PT08.S1(CO) NMHC(GT) Date 2004-03-10 2.6 1360.00 150 2004-03-10 2.0 1292.25 112 2004-03-10 2.2 1402.00 88
We successfully ingested the data from the CSV file in GitHub into a DataFrame and printed the first three rows of select columns.
Reading data from a public S3 bucket
AWS supports virtual-hosted-style URLs such as https://bucket-name.s3.Region.amazonaws.com/keyname, path-style URLs such as https://s3.Region.amazonaws.com/bucket-name/keyname, and using S3://bucket/keyname. Here are examples of how these different URLs may look for our file:
- A virtual hosted-style URL or an object URL: https://tscookbook.s3.us-east-1.amazonaws.com/AirQualityUCI.xlsx
- A path-style URL: https://s3.us-east-1.amazonaws.com/tscookbook/AirQualityUCI.xlsx
- An S3 protocol:
s3://tscookbook/AirQualityUCI.csv
In this example, you will be reading the AirQualityUCI.xlsx file, which has only one sheet. It contains the same data as AirQualityUCI.csv, which we read earlier from GitHub.
Note that in the URL, you do not need to specify the region as us-east-1. The us-east-1 region, which represents US East (North Virginia), is an exception and will not be the case for other regions:
url = 'https://tscookbook.s3.amazonaws.com/AirQualityUCI.xlsx' df = pd.read_excel(url, index_col='Date', parse_dates=True)
Read the same file using the S3:// URL:
s3uri = 's3://tscookbook/AirQualityUCI.xlsx' df = pd.read_excel(s3uri, index_col='Date', parse_dates=True)
You may get an error such as the following:
ImportError: Install s3fs to access S3
This indicates that either you do not have the s3fs library installed or possibly you are not using the right Python/Conda environment.
Reading data from a private S3 bucket
When reading files from a private S3 bucket, you will need to pass your credentials to authenticate. A convenient parameter in many of the I/O functions in pandas is storage_options, which allows you to send additional content with the request, such as a custom header or required credentials to a cloud service.
You will need to pass a dictionary (key-value pair) to provide the additional information along with the request, such as username, password, access keys, and secret keys to storage_options as in {"username": username, "password": password}.
Now, you will read the AirQualityUCI.csv file, located in a private S3 bucket:
- You will start by storing your AWS credentials in a config
.cfgfile outside your Python script. Then, useconfigparserto read the values and store them in Python variables. You do not want your credentials exposed or hardcoded in your code:# Example aws.cfg file
[AWS]
aws_access_key=your_access_key
aws_secret_key=your_secret_key
You can load the aws.cfg file using config.read():
import configparser
config = configparser.ConfigParser()
config.read('aws.cfg')
AWS_ACCESS_KEY = config['AWS']['aws_access_key']
AWS_SECRET_KEY = config['AWS']['aws_secret_key']
- The AWS Access Key ID and Secret Access Key are now stored in A
WS_ACCESS_KEYandAWS_SECRET_KEY.Usepandas.read_csv()to read the CSV file and update thestorage_optionsparameter by passing your credentials, as shown in the following code:s3uri = "s3://tscookbook-private/AirQuality.csv"
df = pd.read_csv(s3uri,
index_col='Date',
parse_dates=True,
storage_options= {'key': AWS_ACCESS_KEY,
'secret': AWS_SECRET_KEY
})
df.iloc[:3, 1:4]
>>
CO(GT) PT08.S1(CO) NMHC(GT)
Date
2004-10-03 2.6 1360.0 150.0
2004-10-03 2.0 1292.0 112.0
2004-10-03 2.2 1402.0 88.0
- Alternatively, you can use the AWS SDK for Python (Boto3) to achieve similar results. The
boto3Python library gives you more control and additional capabilities (beyond just reading and writing to S3). You will pass the same credentials stored earlier inAWS_ACCESS_KEYandAWS_SECRET_KEYand pass them to AWS, usingboto3to authenticate:import boto3
bucket = "tscookbook-private"
client = boto3.client("s3",aws_access_key_id =AWS_ACCESS_KEY,
aws_secret_access_key = AWS_SECRET_KEY)
Now, the client object has access to many methods specific to the AWS S3 service for creating, deleting, and retrieving bucket information, and more. In addition, Boto3 offers two levels of APIs: client and resource. In the preceding example, you used the client API.
The client is a low-level service access interface that gives you more granular control, for example, boto3.client("s3"). The resource is a higher-level object-oriented interface (an abstraction layer), for example, boto3.resource("s3").
In Chapter 4, Persisting Time Series Data to Files, you will explore the resource API interface when writing to S3. For now, you will use the client interface.
- You will use the
get_objectmethod to retrieve the data. Just provide the bucket name and a key. The key here is the actual filename:data = client.get_object(Bucket=bucket, Key='AirQuality.csv')
df = pd.read_csv(data['Body'],
index_col='Date',
parse_dates=True)
df.iloc[:3, 1:4]
>>
CO(GT) PT08.S1(CO) NMHC(GT)
Date
2004-10-03 2,6 1360.0 150.0
2004-10-03 2 1292.0 112.0
2004-10-03 2,2 1402.0 88.0
When calling the client.get_object() method, a dictionary (key-value pair) is returned, as shown in the following example:
{'ResponseMetadata': {
'RequestId':'MM0CR3XX5QFBQTSG',
'HostId':'vq8iRCJfuA4eWPgHBGhdjir1x52Tdp80ADaSxWrL4Xzsr
VpebSZ6SnskPeYNKCOd/RZfIRT4xIM=',
'HTTPStatusCode':200,
'HTTPHeaders': {'x-amz-id-2': 'vq8iRCJfuA4eWPgHBGhdjir1x52
Tdp80ADaSxWrL4XzsrVpebSZ6SnskPeYNKCOd/RZfIRT4xIM=',
'x-amz-request-id': 'MM0CR3XX5QFBQTSG',
'date': 'Tue, 06 Jul 2021 01:08:36 GMT',
'last-modified': 'Mon, 14 Jun 2021 01:13:05 GMT',
'etag': '"2ce337accfeb2dbbc6b76833bc6f84b8"',
'accept-ranges': 'bytes',
'content-type': 'binary/octet-stream',
'server': 'AmazonS3',
'content-length': '1012427'},
'RetryAttempts': 0},
'AcceptRanges': 'bytes',
'LastModified': datetime.datetime(2021, 6, 14, 1, 13, 5, tzinfo=tzutc()),
'ContentLength': 1012427,
'ETag': '"2ce337accfeb2dbbc6b76833bc6f84b8"',
'ContentType': 'binary/octet-stream',
'Metadata': {},
'Body': <botocore.response.StreamingBody at 0x7fe9c16b55b0>}
The content you are interested in is in the response body under the Body key. You passed data['Body'] to the read_csv() function, which loads the response stream (StreamingBody) into a DataFrame.
Reading data from HTML
pandas offers an elegant way to read HTML tables and convert the content into a pandas DataFrame using the pandas.read_html() function:
- In the following recipe, we will extract HTML tables from Wikipedia for COVID-19 pandemic tracking cases by country and by territory (https://en.wikipedia.org/wiki/COVID-19_pandemic_by_country_and_territory):
url = "https://en.wikipedia.org/wiki/COVID-19_pandemic_by_country_and_territory"
results = pd.read_html(url)
print(len(results))
>> 71
pandas.read_html()returned a list of DataFrames, one for each HTML table found in the URL. Keep in mind that the website's content is dynamic and gets updated regularly, and the results may vary. In our case, it returned 71 DataFrames. The DataFrame at index15contains summary on COVID-19 cases and deaths by region. Grab the DataFrame (at index15) and assign it to thedfvariable, and print the returned columns:df = results[15]
df.columns
>> Index(['Region[28]', 'Total cases', 'Total deaths', 'Cases per million',
'Deaths per million', 'Current weekly cases', 'Current weekly deaths',
'Population millions', 'Vaccinated %[29]'],
dtype='object')
- Display the first five rows for
Total cases,Total deaths, and theCases per millioncolumns.df[['Total cases', 'Total deaths', 'Cases per million']].head()
>>
Total cases Total deaths Cases per million
0 139300788 1083815 311412
1 85476396 1035884 231765
2 51507114 477420 220454
3 56804073 1270477 132141
4 21971862 417507 92789
How it works…
Most of the pandas reader functions accept a URL as a path. Examples include the following:
pandas.read_csv()pandas.read_excel()pandas.read_parquet()pandas.read_table()pandas.read_pickle()pandas.read_orc()pandas.read_stata()pandas.read_sas()pandas.read_json()
The URL needs to be one of the valid URL schemes that pandas supports, which includes http and https, ftp, s3, gs, or the file protocol.
The read_html() function is great for scraping websites that contain data in HTML tables. It inspects the HTML and searches for all the <table> elements within the HTML. In HTML, table rows are defined with the <tr> </tr> tags and headers with the <th></th> tags. The actual data (cell) is contained within the <td> </td> tags. The read_html() function looks for <table>, <tr>, <th>, and <td> tags and converts the content into a DataFrame, and assigns the columns and rows as they were defined in the HTML. If an HTML page contains more than one <table></table> tag, read_html will return them all and you will get a list of DataFrames.
The following code demonstrates how pandas.read_html()works:
import pandas as pd html = """ <table> <tr> <th>Ticker</th> <th>Price</th> </tr> <tr> <td>MSFT</td> <td>230</td> </tr> <tr> <td>APPL</td> <td>300</td> </tr> <tr> <td>MSTR</td> <td>120</td> </tr> </table> </body> </html> """ df = pd.read_html(html) df[0] >> Ticker Price 0 MSFT 230 1 APPL 300 2 MSTR 120
In the preceding code, the read_html() function parsed the HTML code and converted the HTML table into a pandas DataFrame. The headers between the <th> and </th> tags represent the column names of the DataFrame, and the content between the <tr><td> and </td></tr> tags represent the row data of the DataFrame. Note that if you go ahead and delete the <table> and </table> table tags, you will get the ValueError: No tables found error.
There's more…
The read_html() function has an optional attr argument, which takes a dictionary of valid HTML <table> attributes, such as id or class. For example, you can use the attr parameter to narrow down the tables returned to those that match the class attribute sortable as in <table class="sortable">. The read_html function will inspect the entire HTML page to ensure you target the right set of attributes.
In the previous exercise, you used the read_html function on the COVID-19 Wikipedia page, and it returned 71 tables (DataFrames). The number of tables will probably increase as time goes by as Wikipedia gets updated. You can narrow down the result set and guarantee some consistency by using the attr option. First, start by inspecting the HTML code using your browser. You will see that several of the <table> elements have multiple classes listed, such as sortable. You can look for other unique identifiers.
<table class="wikitable sortable mw-datatable covid19-countrynames jquery-tablesorter" id="thetable" style="text-align:right;">
Note, if you get the error html5lib not found, please install it you will need to install both html5lib and beautifulSoup4.
To install using conda, use the following:
conda install html5lib beautifulSoup4
To install using pip, use the following:
pip install html5lib beautifulSoup4
Now, let's use the sortable class and request the data again:
url = "https://en.wikipedia.org/wiki/COVID-19_pandemic_by_country_and_territory"
df = pd.read_html(url, attrs={'class': 'sortable'})
len(df)
>> 7
df[3].columns
>>
Index(['Region[28]', 'Total cases', 'Total deaths', 'Cases per million',
'Deaths per million', 'Current weekly cases', 'Current weekly deaths',
'Population millions', 'Vaccinated %[29]'],
dtype='object')
The list returned a smaller subset of tables (from 71 down to 7).
See also
For more information, please refer to the official pandas.read_html documentation: https://pandas.pydata.org/docs/reference/api/pandas.read_html.html.


