






















































Measuring classification performance
The standard approach for any ML problem incorporates different classification algorithms and examines which works best. Previously, we used two classification methods for the spam filtering problem, but our job is not done yet; we need to evaluate their performance in more detail. Therefore, this section presents a deeper discussion on standard evaluation metrics for this task.
Calculating accuracy
If you had to choose only one of the two created models for a production system, which would that be? The spontaneous answer is to select the one with the highest accuracy. The argument is that the algorithm with the highest number of correct classifications should be the right choice. Although this is not far from the truth, it is not always the case. Accuracy is the percentage of correctly classified examples by an algorithm divided by the total number of examples:
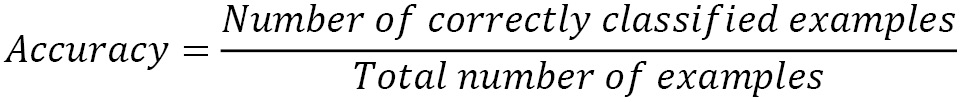
Suppose that a dataset consists of 1,000 labeled emails. Table 2.8 shows a possible outcome after classifying the samples:
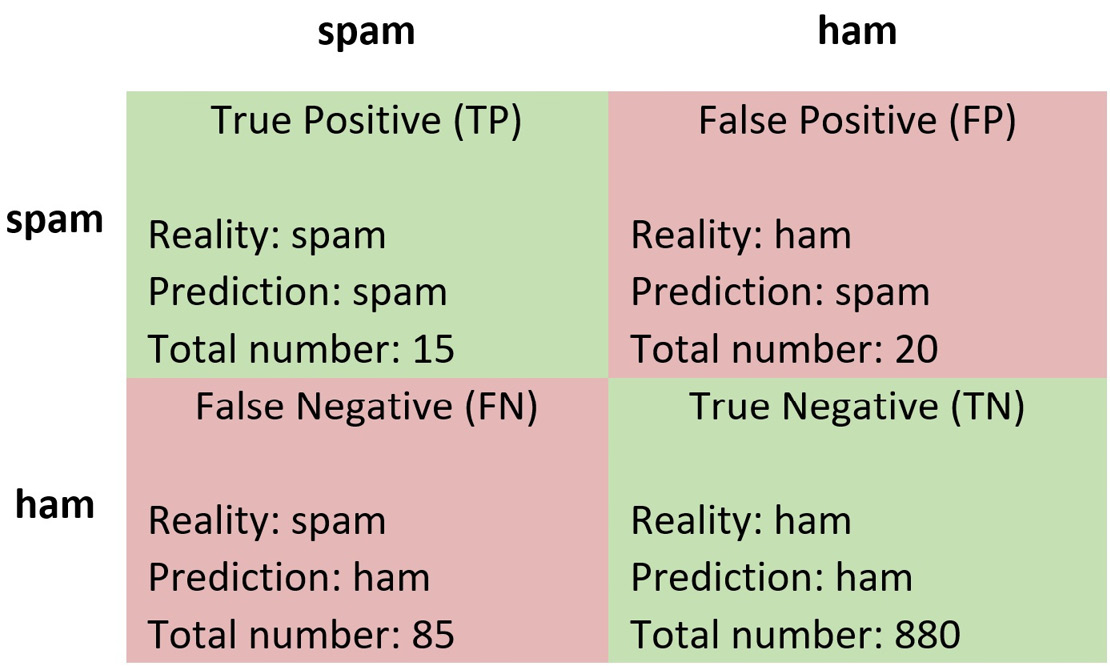
Table 2.8 – A confusion matrix after classifying 1,000 emails
Each cell contains information about the following:
- The correct label of the sample (Reality)
- The classification result (Prediction)
- Total number of samples
For example, 85 emails are labeled as ham, but they are, in reality, spam (in the bottom-left cell). This table, known as a confusion matrix, is used to evaluate the performance of a classification model and provide a better insight into the types of error. Ideally, we would prefer all model predictions to appear in the main diagonal (True Positive and True Negative). From the matrix, we can immediately observe that the dataset is imbalanced, as it contains 100 spam emails and 900 ham ones.
We can rewrite the formula for accuracy based on the previous information as follows:
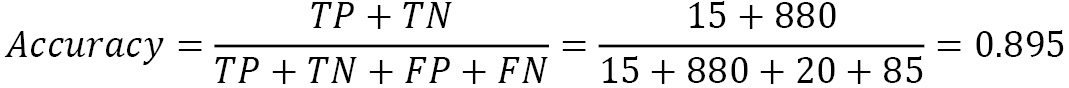
89.5% of accuracy doesn’t seem that bad, but a closer look at the data reveals a different picture. Out of the 100 spam emails (TPs + FNs), only 15 are identified correctly, and the other 85 are labeled as ham emails. Alas, this score is a terrible result indeed! To assess the performance of a model correctly, we need to make this analysis and consider the type of errors that are most important within the task. Is it better to have a strict model that can block a legitimate email for the sake of fewer spam ones (increased FPs)? Or is it preferable to have a lenient model that doesn’t block most ham emails but allows more undetected spam in your mailbox (increased FNs)?
Similar questions arise in all ML problems and generally in many real-world situations. For example, wrong affirmative decisions (FPs) in a fire alarm system are preferable to wrong negative ones (FNs). In the first case, we get a false alert of a fire that didn’t occur. Conversely, declaring innocent a guilty prisoner implies higher FNs, which is preferable to finding guilty an innocent one (higher FPs). Accuracy is a good metric when the test data is balanced and the classes are equally important.
In the following Python code, we calculate the accuracy for a given test set:
from sklearn import metrics # Get the predicted classes. test_class_pred = nb_classifier.predict(test_data_features.toarray()) # Calculate the accuracy on the test set. metrics.accuracy_score(test_class, test_class_pred) >> 0.8571428571428571
Accuracy is a prominent and easy-to-interpret metric for any ML problem. As already discussed, however, it poses certain limitations. The following section focuses on metrics that shed more light on the error types.
Calculating precision and recall
Aligned with the previous discussion, we can introduce two evaluation metrics: precision and recall. First, precision tells us the proportion of positive identifications that are, in reality, correct, and it’s defined as the following (with the numbers as taken from Table 2.8):
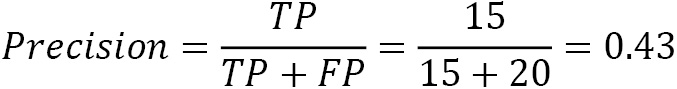
In this case, only 43% of all emails identified as spam are actually spam. The same percentage in a medical screening test suggests that 43% of patients classified as having the disease genuinely have it. A model with zero FPs has a precision equal to 1.
Recall, on the other hand, tells us the proportion of the actual positives that are identified correctly, and it’s defined as the following:
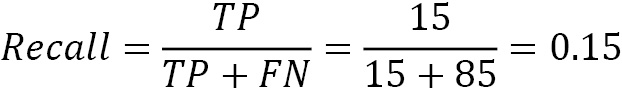
Here, the model identifies only 15% of all spam emails. Ditto, 15% of the patients with a disease are classified as having the disease, while 85 sick people remain undiagnosed. A model with zero FNs has a recall equal to 1. Improving precision often deteriorates recall and vice versa (remember the discussion on strict and lenient models in the previous section).
We can calculate both metrics in the following code using the Naïve Bayes model:
# Calculate the precision on the test set. metrics.precision_score(test_class, test_class_pred) >> 0.8564814814814815
After calculating precision, we do the same for recall:
# Calculate the recall on the test set. metrics.recall_score(test_class, test_class_pred) >> 1.0
Notice that in this case, recall is equal to 1.0, suggesting the model captured all spam emails. Equipped with the necessary understanding of these metrics, we can continue on the same path and introduce another typical score.
Calculating the F-score
We can combine precision and recall in one more reliable F-score metric: their harmonic mean, given by the following equation:
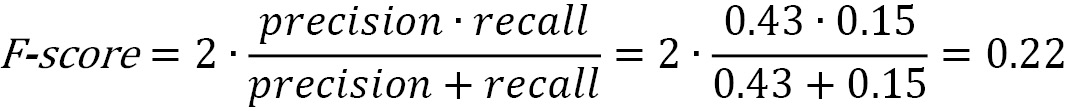
When precision and recall reach their perfect score (equal to 1), the F-score becomes 1. In the following code, we calculate the F-score comparing the actual class labels in the test set and the ones predicted by the model:
# Calculate the F-score on the test set. metrics.f1_score(test_class, test_class_pred) >> 0.9226932668329177
As we can observe, the Naïve Bayes model has an F-score equal to 0.92. Running the same code for the SVM case gives an F-score of 0.93.
The following section discusses another typical evaluation metric.
Creating ROC and AUC
When the classifier returns some kind of confidence score for each prediction, we can use another technique for evaluating performance called the Receiver Operator Characteristic (ROC) curve. A ROC curve is a graphical plot that shows the model’s performance at all classification thresholds. It utilizes two rates, namely the True Positive Rate (TPR), the same as recall, and the False Positive Rate (FPR), defined as the following:
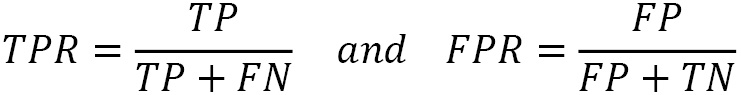
The benefit of ROC curves is that they help us visually identify the trade-offs between the TPR and FPR. In this way, we can find which classification threshold better suits the problem under study. For example, we need to ensure that no important email is lost during spam detection (and consequently, label more spam emails as ham). But, conversely, we must ascertain that all ill patients are diagnosed (and consequently, label more healthy individuals as sick). These two cases require a different trade-off between the TPR and FPR.
Let’s see how to create a ROC curve plot in Table 2.9 using a simplified example with 10 emails and 7 thresholds:
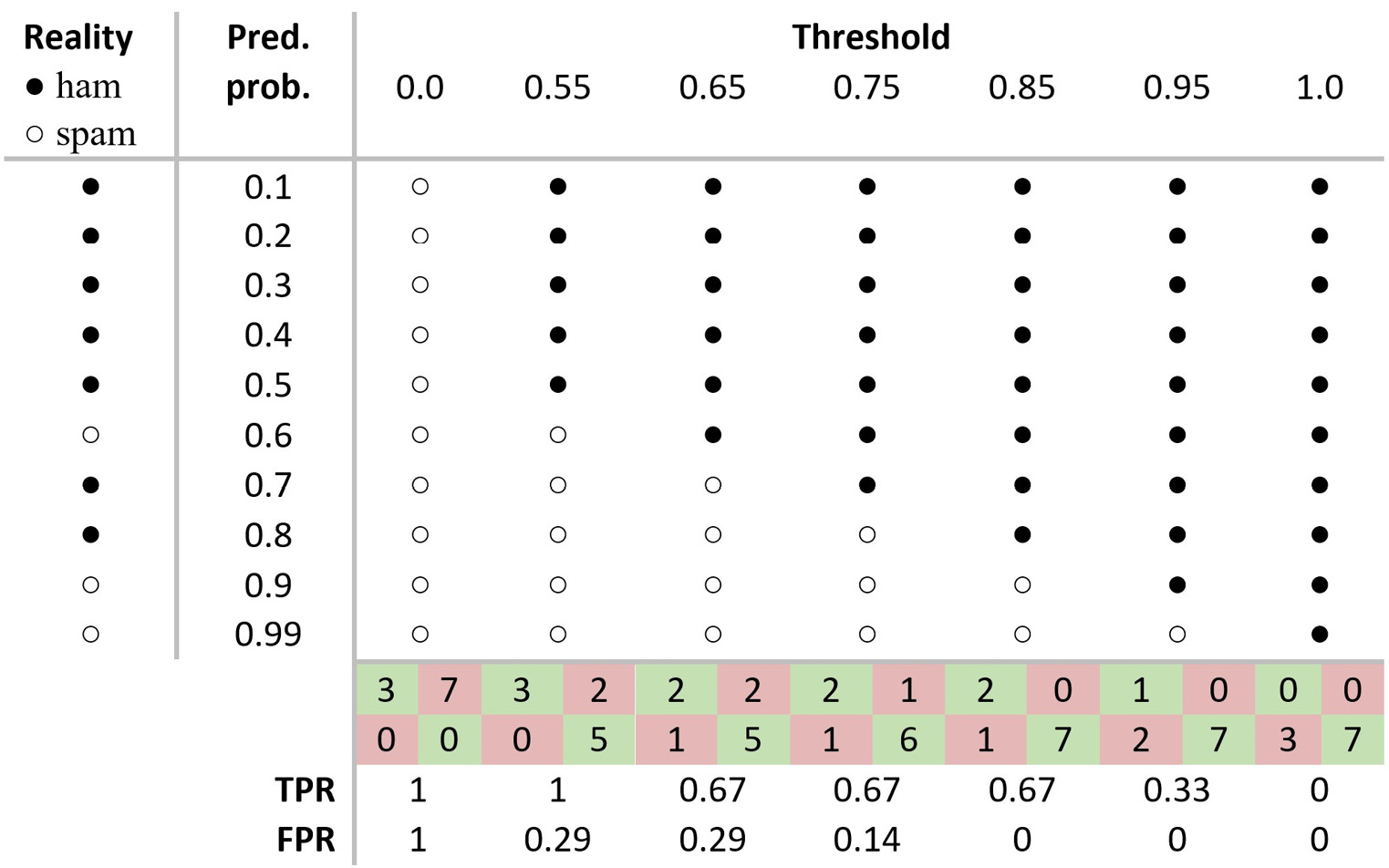
Table 2.9 – Calculating the TPR and FPR scores for different thresholds
For each sample in the first column of the table, we get a prediction score (probability) in the second one. Then, we compare this score with the thresholds. If the score exceeds the threshold, the example is labeled as ham. Observe the first sample in the table, which is, in reality, ham (represented by a black dot). The model outputs a prediction probability equal to 0.1, which labels the sample as ham for all thresholds except the first one. Repeating the same procedure for all samples, we can extract the confusion matrix in each case and calculate the TPR and FPR. Notice that for a threshold equal to 0, the two metrics are equal to 1. Conversely, if the threshold is 1, the metrics are equal to 0.
Figure 2.14 shows the different possible results of this process. The grayed area in these plots, called the Area Under the ROC Curve (AUC), is related to the quality of our model; the higher its surface, the better it is:
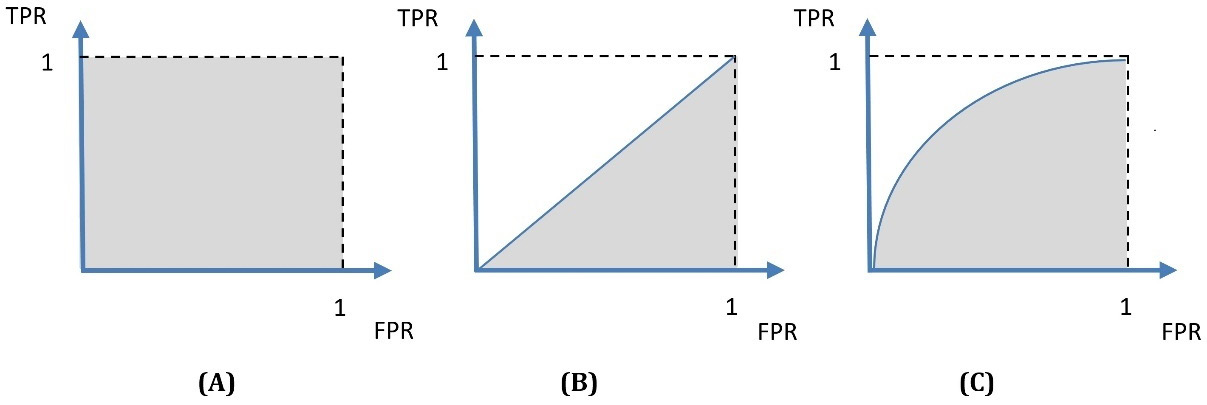
Figure 2.14 – Different ROC curves and their corresponding AUCs
Interesting fact
Radar engineers first developed the ROC curve during World War II for detecting enemy objects on battlefields.
A in Figure 2.14 represents the ideal situation, as there are no classification errors. B in Figure 2.14 represents a random classifier, so if you end up with a similar plot, you can flip a coin and decide on the outcome, as your ML model won’t provide any additional value. However, most of the time, we obtain plots similar to C in Figure 2.14. To summarize, the benefit of ROC curves is twofold:
- We can directly compare different models to find the one with a higher AUC.
- We can specify which TPR and FPR combination offers good classification performance for a specific model.
We can now apply the knowledge about the ROC and AUC to the spam detection problem. In the following code, we perform the necessary steps to create the ROC curves for the two models:
# Create and plot the ROC curves.
nb_disp = metrics.plot_roc_curve(nb_classifier, test_data_features.toarray(), test_class)
svm_disp = metrics.plot_roc_curve(svm_classifier, test_data_features.toarray(), test_class, ax=nb_disp.ax_)
svm_disp.figure_.suptitle("ROC curve comparison")
Figure 2.15 shows the output of this process:
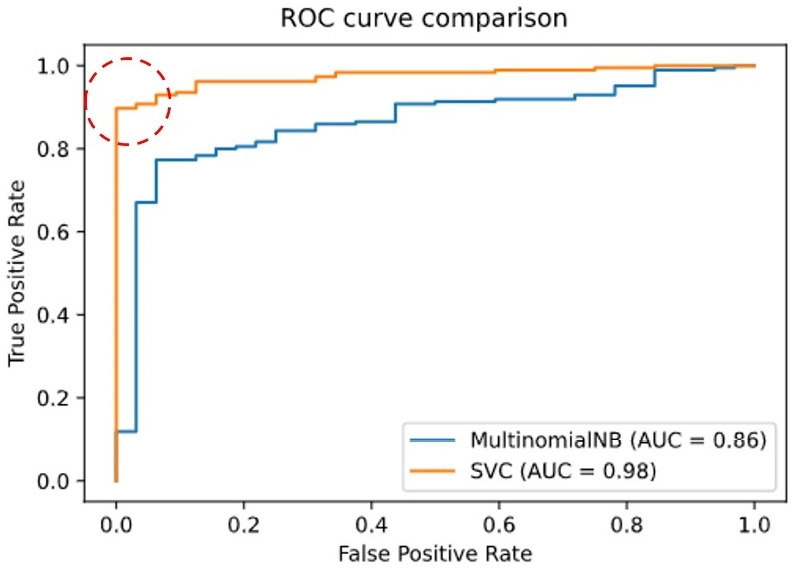
Figure 2.15 – The AUC for the SVM and the Naïve Bayes model
According to the figure, the AUC is 0.98 for the SVM and 0.87 for Naïve Bayes. All results so far corroborate our initial assumption of the superiority of the SVM model. Finally, the best trade-off between the TPR and FPR lies in the points inside the dotted circle. For these points, the TPR is close to 1.0 and the FPR close to 0.0.
Creating precision-recall curves
Before concluding the chapter, let’s cover one final topic. ROC curves can sometimes perform too optimistically with imbalanced datasets. For example, using the TN factor during the FPR calculation can skew the results; look at the disproportional value of TN in Table 2.8. Fortunately, this factor is not part of the precision or recall formulas. The solution, in this case, is to generate another visualization called the Precision-Recall curve. Let’s see how to create the curves for the Naïve Bayes predictions:
- Initially, we extract the ROC:
# Obtain the scores for each prediction. probs = nb_classifier.predict_proba(test_data_features.toarray()) test_score = probs[:, 1] # Compute the Receiver Operating Characteristic. fpr, tpr, thresholds = metrics.roc_curve(test_class, test_score) # Compute Area Under the Curve. roc_auc = metrics.auc(fpr, tpr) # Create the ROC curve. rc_display = metrics.RocCurveDisplay(fpr=fpr, tpr=tpr, roc_auc=roc_auc, estimator_name='MultinomialNB')
- Let’s use the same predictions to create the precision-recall curves:
# Create the precision recall curves. precision, recall, thresholds = metrics.precision_recall_curve(test_class, test_score) ap = metrics.average_precision_score(test_class, test_score) pr_display = metrics.PrecisionRecallDisplay(precision=precision, recall=recall, average_precision=ap, estimator_name='MultinomialNB')
- We can combine and show both plots in one:
# Plot the curves. fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(10, 5)) rc_display.plot(ax=ax1) pr_display.plot(ax=ax2)
The output in Figure 2.16 presents the ROC and precision-recall curves side by side:
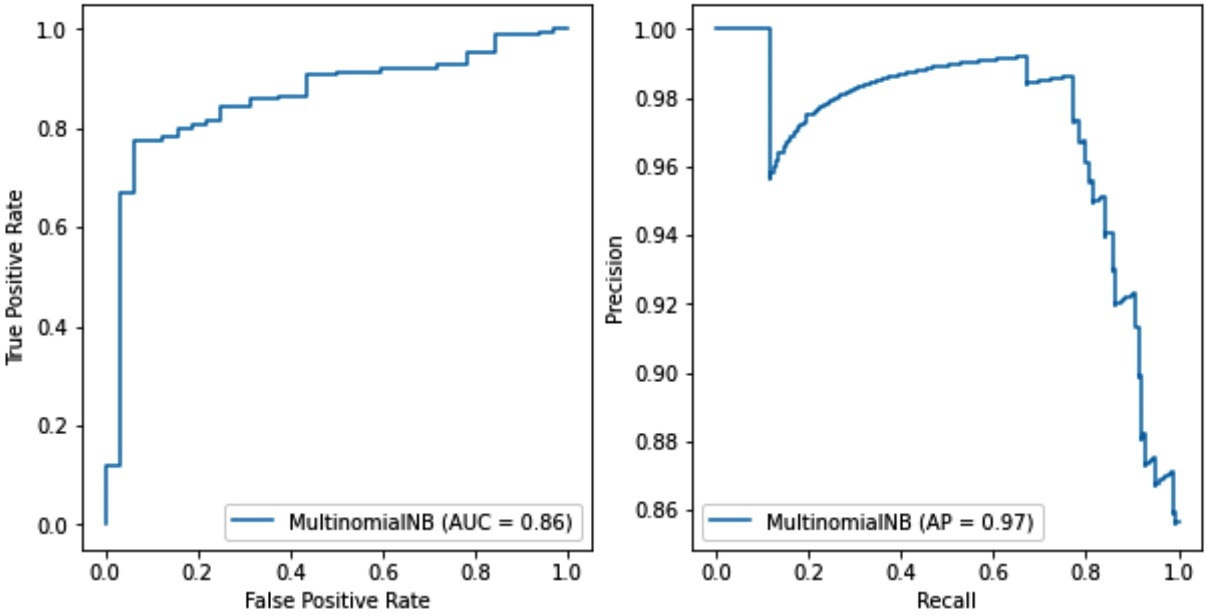
Figure 2.16 – The ROC curve (left) versus the precision-recall curve (right) for the Naïve Bayes model
Both plots summarize the trade-offs between the rates on the x and y axes using different probability thresholds. In the right plot, the average precision (AP) is 0.97 for the Naïve Bayes model and 0.99 for the SVM (not shown). Therefore, we do not observe any mismatch between the ROC and the precision-recall curves concerning which model is better. The SVM is the definite winner! One possible scenario when using imbalance sets is that the TN factor can affect the choice of the best model. In this case, we must scrutinize both types of curves to understand the models’ performance and the differences between the classifiers. The takeaway is that a metric’s effectiveness depends on the specific application and should always be examined from this perspective.

