






















































Acquiring a data pipeline
The Acquire layer contains the data pipeline processes for collecting data from a source system(s), storing the data, sculpting the data, and providing data back to other applications.
Intake tools – importing data from various data sources
This section will discuss the main options in the Domo ecosystem for data intake:
- A connector pulls data into the Domo cloud from files, cloud apps, and databases. It's a Domo application that, through a wizard-like interface, allows a user to select source systems to get data from. The user then simply enters a few configuration inputs and provides credentials in order to copy and store the data in the Domo cloud data warehouse as a dataset.
There is a rapidly growing universe of cloud-based applications. As of the time of writing, the Domo ecosystem supports over 670 cloud app connectors. Domo's connector team constantly keeps the connectors updated to the vendors' current API versions. And they also created an API so that if you can't find the connector you need, you can create your own custom connector.
- Workbench pushes on-premises data from behind firewalls into the Domo cloud. It is a Windows-based application that you can download and install on a Windows machine, sometimes called the universal data connector as it can handle any flat file or database table upload. It typically sits behind a firewall and pushes the data up to the Domo cloud. It mainly uses ODBC queries to connect to databases, and essentially bulk loads the query result into the Domo cloud. Organizations that do not want to whitelist Domo's cloud connectors find this a great solution—avoiding the need for Domo connectors to reach into their systems from the cloud.
Workbench has robust job scheduling and monitoring capabilities and can even listen to a directory and automatically upload new or changing Excel files.
- Federated queries enable access to source data from wherever the data currently resides, for example, in a data lake. It is Domo's data-at-rest acquisition method for organizations with large existing data lakes. It facilitates the need to have a way to use content where it lies rather than having to copy it. So, with federated queries, the data is not permanently persisted in the Domo cloud. Rather, with federated queries, the query data is cached in memory with a time-to-live setting. The time-to-live setting determines how long the query results will persist in memory before a new request causes a re-query or simply times out and is released. Federated queries effectively make Domo Analyzer a powerful data lake discovery tool and unlock data lake information without any data transport requirement.
- Internet of Things (IoT): Machine-to-machine streaming communication data capture is the newest data acquisition type supported in the Domo ecosystem. This area addresses capturing the information flowing from internet devices and machine sensor data. Existing connectors include AWS IoT Core, AWS IoT Device Management, AWS IoT Device Defender, AWS IoT Analytics, AWS Kinesis, OPC, Matomo, Apache Kafka, MQTT, Particle.io, Beonic Traffic, and more. Domo has partnered with AWS and Verizon ThingSpace to bring innovative solutions to the market. Another example is how SharkNinja is using Domo IoT to improve the customer experience using sensor data: https://bit.ly/32I44w7.
- Webforms are your go-to tool when you just need a simple brute-force way to get data into the Domo cloud. You can enter or cut and paste tabular data into a webform. Think of it as a cloud spreadsheet lite. This is used for lookup table creation, test data, and other miscellaneous needs to create a dataset on the fly.
Store – automatic schema management and performance optimization
Figuring out where and how to store data can be a time-consuming and costly exercise. After you have decided on a structure and location to store the data, then the ongoing process of tuning the data structure so that it is performant requires specialized technical skills. All this means that the storage problem can become a significant obstacle. With Domo, that obstacle is removed via automatic data structure design, storage, and performance tuning, all enabled in a business user-empowering way.
Data architecture (Vault, Adrenaline, Tundra, Federated)
The Domo data architecture consists of four major parts:
- Vault is the persistent storage component that is just a bunch of disk storage. Everything is flattened and stored in tabular arrays called datasets. Vault is a collection of datasets whose data structures are created and cataloged automatically as the data is ingested. The acquired data is physically stored in leading cloud infrastructure providers such as Amazon S3 or Azure.
- Adrenaline is an in-memory data store indexing vault datasets for high query performance. The Domo visuals, beast modes, and filters run a query language called DQL (short for Domo Query Language) against Adrenaline to retrieve the data for the visual.
- Tundra is a specialized in-memory query optimizer companion to Adrenaline and handles queries that specifically fit its optimization algorithm.
- Federated storage is virtually mapped into the Domo ecosystem but is physically stored outside of Domo. If you already have a data lake, then federated queries, which work on federated storage, are a good option. All the preceding storage components work seamlessly together. Behind the scenes, the Domo operations team works to monitor and tune the performance for you.
Cloud data lakes
Importantly, UI components are built on top of the storage layer that showcases the cloud data lake user artifacts. The basic data lake user artifacts are data sources, dataflows, and datasets. Users can search, manage, and enhance the data lake user artifacts. Conveniently, the data lake catalog and data lineage information are auto-generated and can be tag enhanced by the users for the data dictionary. The UI even shows in real time how the data is flowing into the data lake. All the external data sources are represented in the outermost ring of the platter. The data source platter's inner ring shows the data sources created from data sculpting as shown in Figure 1.2:
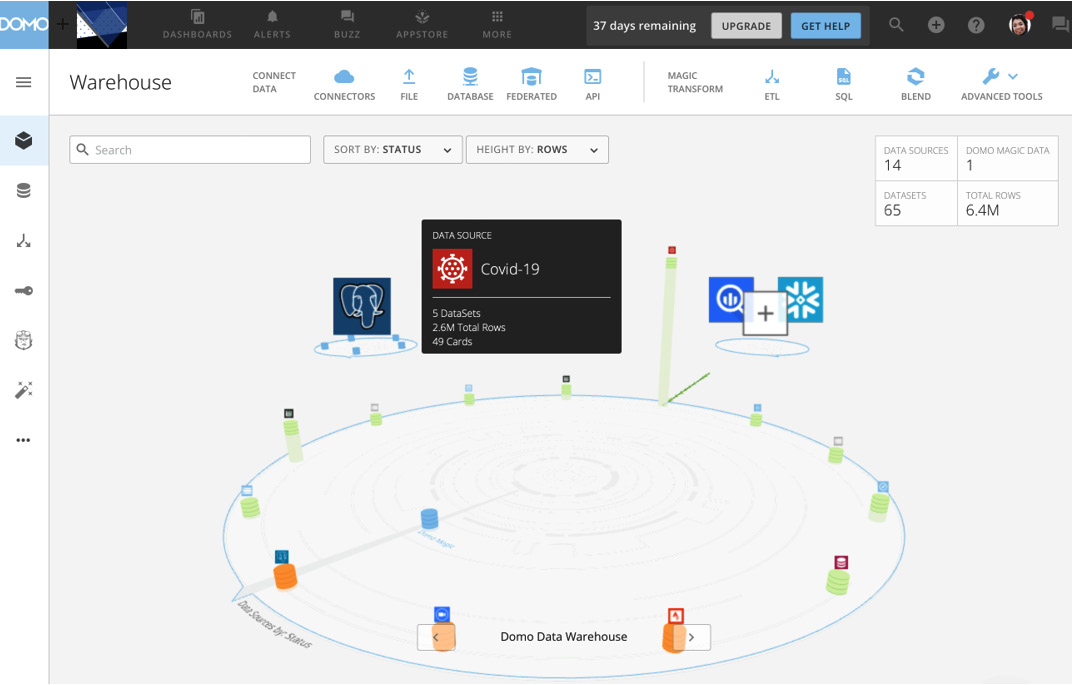
Figure 1.2 – Data source platter
Additionally, to see datasets derived from the data source, you click on a particular data source and then another platter layer opens containing the dataset(s), as seen in Figure 1.3:
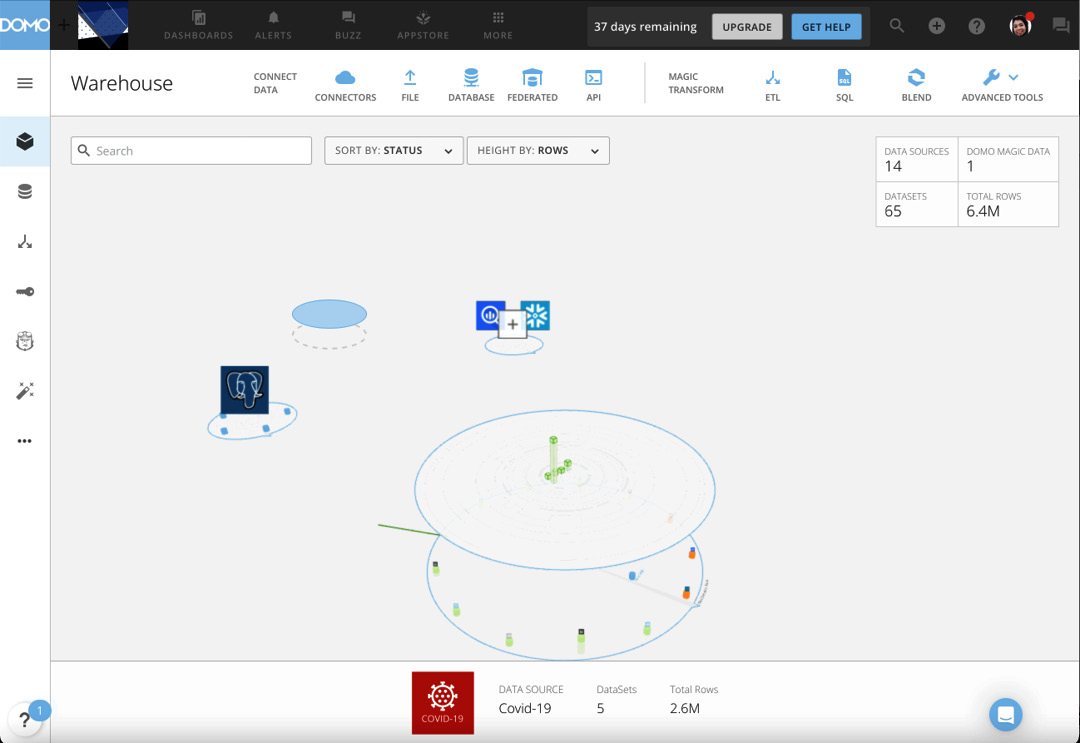
Figure 1.3 – Datasets platter
Data sculpting
Data sculpting tools are not new; for example, Informatica, Boomi, Alteryx, and so on have been around for years. Some have limitations regarding the lack of auto schema discovery, and the lack of auto-generated, non-siloed data cataloging. This leads to a cumbersome data sculpting experience. Domo's data sculpting tools are schema-aware and integrated from source to report. This enables the user to see potential reuse or do new transforms on data quickly. The fully integrated and schema-aware data sculpting toolset includes the ability to stitch data together and transform data, similar to well-known ETL tools. Primarily, it's a no-code, visual programming paradigm for greater adoption. Secondarily, for those SQL scripters out there, a SQL serialization tool is available as well. As you will see, the integration and ease of use truly democratize the data sculpting activity.
Magic ETL
Magic ETL is a drag-and-drop, no-code data sculpting tool that enables a typical user to sculpt the data they have acquired into Domo Vault. It leverages the Apache Spark framework and is a simple yet powerful visual data transformation tool. Transforms include text, date, and number operations. Custom formulas, parsing, and mapping operations are provided, as are filter and de-duplication operations. Of course, merge and join operations are included along with aggregation and pivot operations. Additionally, data science operations for classification, clustering, forecasting, outlier detection, multivariate outliers, and prediction are available and can be automated via Python and R scripting support.
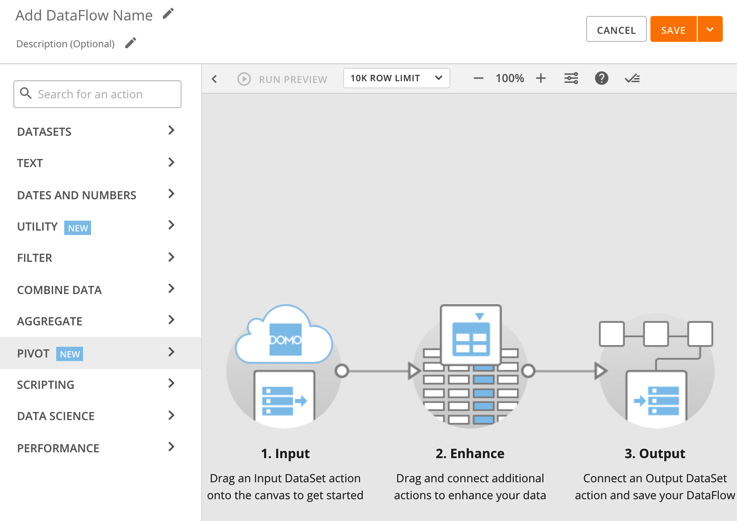
Figure 1.4 – Magic ETL
Magic SQL
The Magic sculpting tools have evolved over time from scripting to no code. Magic ETL is the newest no-code data sculpting tool while MySQL Dataflows, which is a Structured Query Language (SQL) tool supporting serialized SQL statement execution, was the original sculpting tool option. MySQL Dataflows runs on dynamic MySQL instances and is perfect for the SQL developer who doesn't want to transition to Magic ETL; although, it is not as scalable as Magic ETL.
Blend
Blend, formally Fusion, is the Domo equivalent of a VLOOKUP function in Excel creating a new virtual dataset by adding additional information to the primary dataset by combining data from the lookup dataset. It also has properties that allow functions to append datasets like a UNION operation in SQL.
Data Views
Data Views is a new feature that enables users to create aggregates and/or filtered views on an underlying dataset as well as join to other datasets. This feature is very similar to views available on relational databases. Views in Domo are non-materialized but can be materialized using a Magic ETL dataflow.
Important Note
Because Domo is integrated from bottom to top, the data sculpting jobs can be triggered to run when any of the source data changes. No more worrying about batch window timing because the job will run when the source data has changed. Of course, the jobs can also run on a specific time schedule as needed.
Outtaking data
Don't leave your insights stranded. A crucial part of any data platform resides in the ability of other systems to outtake data. Several ways exist to export data from the Domo cloud.
Exporting
The first question many analysts ask when evaluating Domo as a platform is What are the options to export data? So, the product makes sure that getting data exported to Excel is simple, fast, and always possible.
In addition to Excel exports, there are PowerPoint exports and add-ins for Excel and PowerPoint live data embedding.
Finally, there is a RESTful data API for those who want to hit Vault directly to retrieve data.
Writeback connectors
A relatively new feature is writeback connectors. As the name implies, this allows Domo to write data in Domo directly into other systems. A quick search in Domo for writeback connectors reveals 22 connectors to many popular systems, as seen in Figure 1.5. Specific writeback connectors are part of Domo Integration Cloud and require your Domo account team to unlock the feature for your use.

Figure 1.5 – Writeback connectors
RESTful API
For those interested in taking a code-based approach to extracting data from Domo, a RESTful API exists to extract data from the Domo cloud as well: https://developer.domo.com/docs/dev-studio-references/data-api.
Now that we have examined the data acquisition pipeline (Intake, Store, Sculpt, and Outtake), it's time to discuss options for presenting the data.


