Off-Policy MC Control
The algorithm for the off-policy MC control method is given as follows:
- Initialize the Q function Q(s, a) with random values and set the behavior policy b to be epsilon-greedy, set the target policy
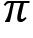 to be greedy policy and initialize the cumulative weights as C(s, a) = 0
to be greedy policy and initialize the cumulative weights as C(s, a) = 0 - For M number of episodes:
- Generate an episode using the behavior policy b
- Initialize return R to 0 and weight W to 1
- For each step t in the episode, t = T – 1, T – 2, . . . , 0:
- Compute the return as R = R + rt+1
- Update the cumulative weights to C(st, at) = C(st, at) +W
- Update the Q value to

- Compute the target policy

- If
 then break
then break - Update the weight to

- Return the target policy