






















































Making a machine think like a human is one of the oldest dreams. Machine learning techniques are used to help make predictions based on experiences and data.
Artificial intelligence and machine learning
Machine learning models and algorithms
In order to teach machines how to solve a large number of problems by themselves, we need to consider the different machine learning models. As you know, we need to feed the model with data; that is why machine learning models are divided, based on datasets entered (input), into four major categories: supervised learning, semi-supervised learning, unsupervised learning, and reinforcement. In this section, we are going to describe each model in a detailed way, in addition to exploring the most well-known algorithms used in every machine learning model. Before building machine learning systems, we need to know how things work underneath the surface.
Supervised
We talk about supervised machine learning when we have both the input variables and the output variables. In this case, we need to map the function (or pattern) between the two parties. The following are some of the most often used supervised machine learning algorithms.
Bayesian classifiers
According to the Cambridge English Dictionary, bias is the action of supporting or opposing a particular person or thing in an unfair way, allowing personal opinions to influence your judgment. Bayesian machine learning refers to having a prior belief, and updating it later by using data. Mathematically, it is based on the Bayes formula:
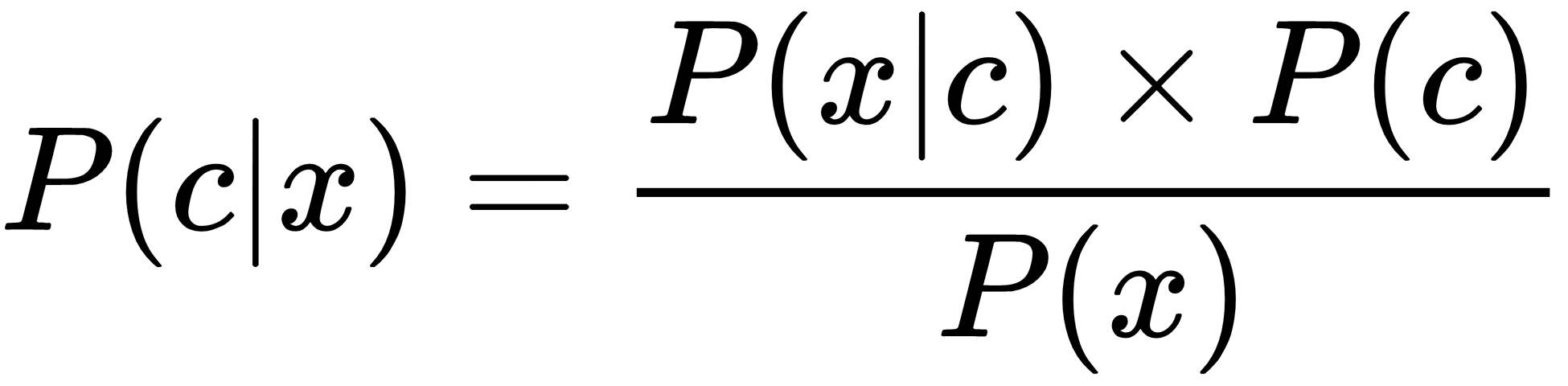
One of the simplest Bayesian problems is randomly tossing a coin and trying to predict whether the output will be heads or tails. That is why we can identify Bayesian methodology as being probabilistic. Naive Bayes is very useful when you are using a small amount of data.
Support vector machines
A support vector machine (SVM) is a supervised machine learning model that works by identifying a hyperplane between represented data. The data can be represented in a multidimensional space. Thus, SVMs are widely used in classification models. In an SVM, the hyperplane that best separates the different classes will be used. In some cases, when we have different hyperplanes that separate different classes, identification of the correct one will be performed thanks to something called a margin, or a gap. The margin is the nearest distance between the hyperplanes and the data positions. You can take a look at the following representation to check for the margin:
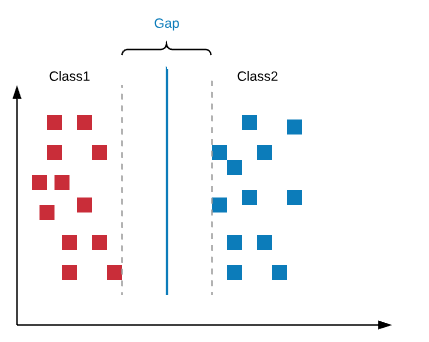
The hyperplane with the highest gap will be selected. If we choose the hyperplane with the shortest margin, we might face misclassification problems later. Don't be distracted by the previous graph; the hyperplane will not always be linear. Consider a case like the following:
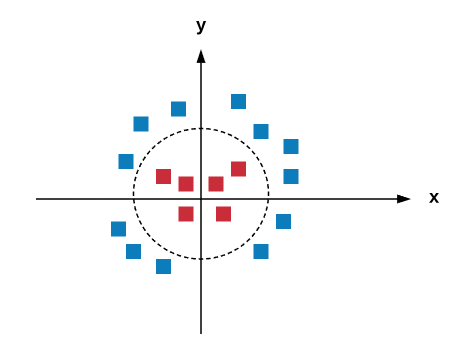
In the preceding situation, we can add a new axis, called the z axis, and apply a transformation using a kernel trick called a kernel function, where z=x^2+y^2. If you apply the transformation, the new graph will be as follows:
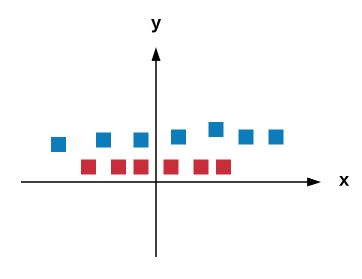
Now, we can identify the right hyperplane. The transformation is called a kernel. In the real world, finding a hyperplane is very hard. Thus, two important parameters, called regularization and gamma, play a huge role in the determination of the right hyperplane, and in every SVM classifier to obtain better accuracy in nonlinear hyperplane situations.
Decision trees
Decision trees are supervised learning algorithms used in decision making by representing data as trees upside-down with their roots at the top. The following is a graphical representation of a decision tree:
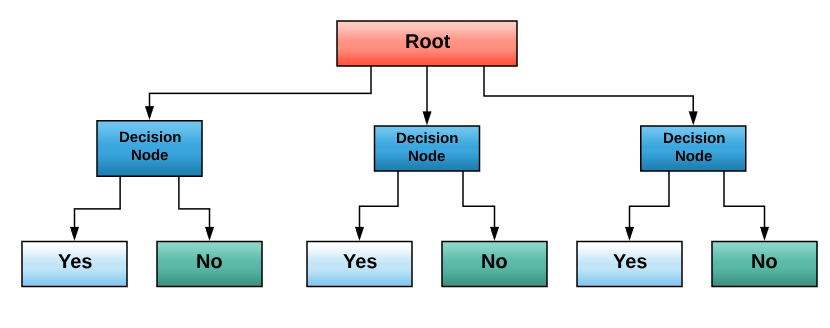
Data is represented thanks to the Iterative Dichotomiser 3 algorithm. Decision trees used in classification and regression problems are called CARTs. They were introduced by Leo Breiman.
Semi-supervised
Semi-supervised learning is an area between the two previously discussed models. In other words, if you are in a situation where you are using a small amount of labeled data in addition to unlabeled data, then you are performing semi-supervised learning. Semi-supervised learning is widely used in real-world applications, such as speech analysis, protein sequence classification, and web content classification. There are many semi-supervised methods, including generative models, low-density separation, and graph-based methods (discrete Markov Random Fields, manifold regularization, and mincut).
Unsupervised
In unsupervised learning, we don't have clear information about the output of the models. The following are some well-known unsupervised machine learning algorithms.
Artificial neural networks
Artificial networks are some of the hottest applications in artificial intelligence, especially machine learning. The main aim of artificial neural networks is building models that can learn like a human mind; in other words, we try to mimic the human mind. That is why, in order to learn how to build neural network systems, we need to have a clear understanding of how a human mind actually works. The human mind is an amazing entity. The mind is composed and wired by neurons. Neurons are responsible for transferring and processing information.
We all know that the human mind can perform a lot of tasks, like hearing, seeing, tasting, and many other complicated tasks. So logically, one might think that the mind is composed of many different areas, with each area responsible for a specific task, thanks to a specific algorithm. But this is totally wrong. According to research, all of the different parts of the human mind function thanks to one algorithm, not different algorithms. This hypothesis is called the one algorithm hypothesis.
Now we know that the mind works by using one algorithm. But what is this algorithm? How is it used? How is information processed with it?
To answer the preceding questions, we need to look at the logical representation of a neuron. The artificial representation of a human neuron is called a perceptron. A perceptron is represented by the following graph:
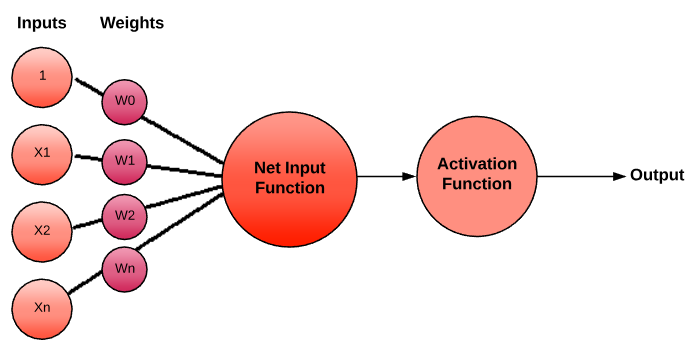
There are many Activation Functions used. You can view them as logical gates:
- Step function: A predefined threshold value.
- Sigmoid function:
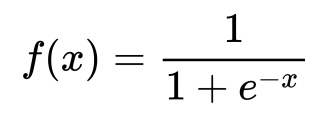
- Tanh function:
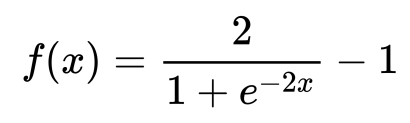
- ReLu function:
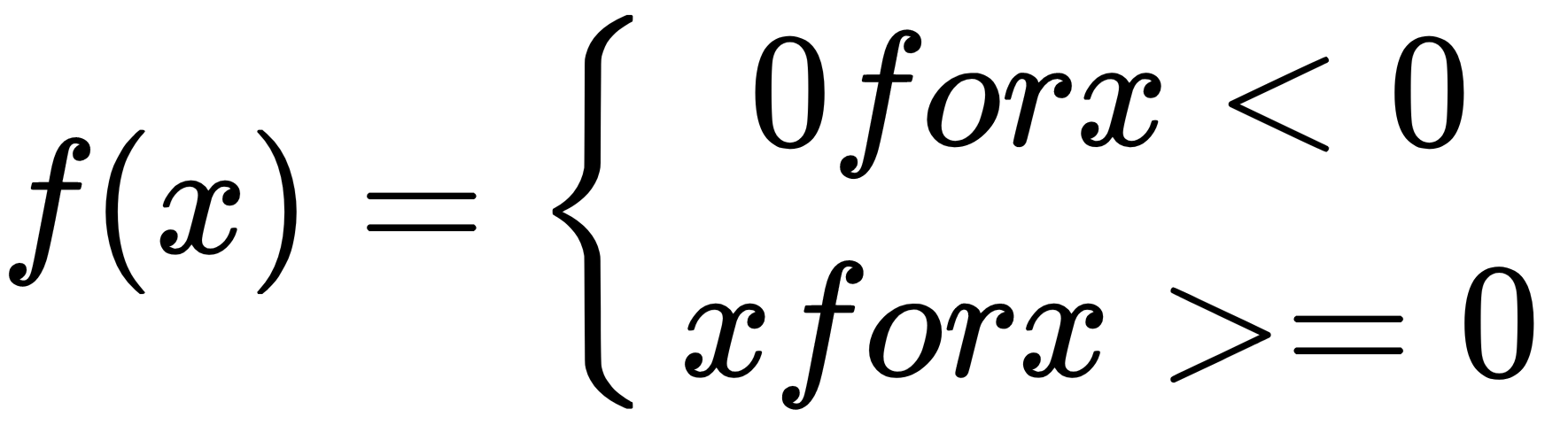
Many fully connected perceptrons comprise what we call a Multi-Layer Perceptron (MLP) network. A typical neural network contains the following:
- An input layer
- Hidden layers
- Output layers
We will discuss the term deep learning once we have more than three hidden layers. There are many types of deep learning networks used in the world:
- Convolutional neural networks (CNNs)
- Recursive neural networks (RNNs)
- Long short-term memory (LSTM)
- Shallow neural networks
- Autoencoders (AEs)
- Restricted Boltzmann machines
Don't worry; we will discuss the preceding algorithms in detail in future chapters.
To build deep learning models, we follow five steps, suggested by Dr. Jason Brownlee. The five steps are as follows:
- Network definition
- Network compiling
- Network fitting
- Network evaluation
- Prediction
Linear regression
Linear regression is a statistical and machine learning technique. It is widely used to understand the relationship between inputs and outputs. We use linear regression when we have numerical values.
Logistic regression
Logistic regression is also a statistical and machine learning technique, used as a binary classifier - in other words, when the outputs are classes (yes/no, true/false, 0/1, and so on).
Clustering with k-means
k-Nearest Neighbors (kNN) is a well-known clustering method. It is based on finding similarities in data points, or what we call the feature similarity. Thus, this algorithm is simple, and is widely used to solve many classification problems, like recommendation systems, anomaly detection, credit ratings, and so on . However, it requires a high amount of memory. While it is a supervised learning model, it should be fed by labeled data, and the outputs are known. We only need to map the function that relates the two parties. A kNN algorithm is non-parametric. Data is represented as feature vectors. You can see it as a mathematical representation:
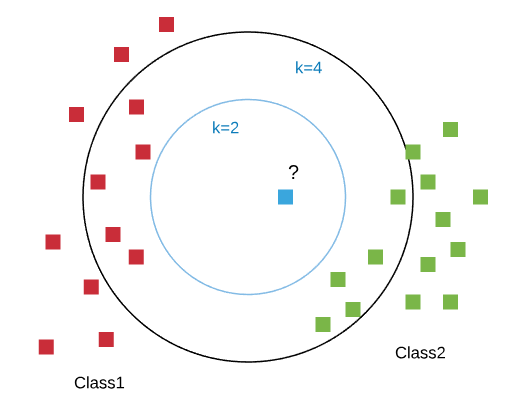
The classification is done like a vote; to know the class of the data selected, you must first compute the distance between the selected item and the other, training item. But how can we calculate these distances?
Generally, we have two major methods for calculating. We can use the Euclidean distance:
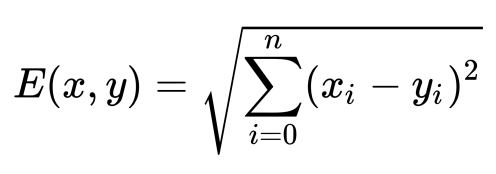
Or, we can use the cosine similarity:
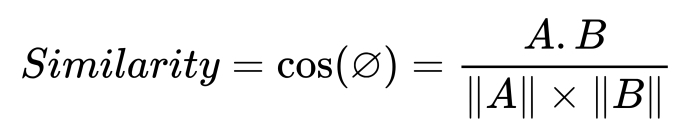
The second step is choosing k the nearest distances (k can be picked arbitrarily). Finally, we conduct a vote, based on a confidence level. In other words, the data will be assigned to the class with the largest probability.
Reinforcement
In the reinforcement machine learning model, the agent is in interaction with its environment, so it learns from experience, by collecting data during the process; the goal is optimizing what we call a long term reward. You can view it as a game with a scoring system. The following graph illustrates a reinforcement model:
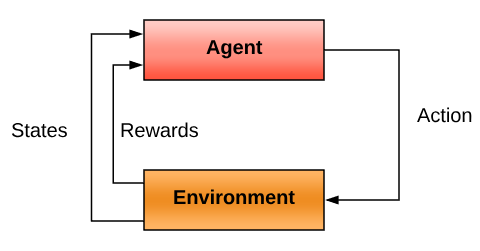
Performance evaluation
Evaluation is a key step in every methodological operation. After building a product or a system, especially a machine learning model, we need to have a clear vision about its performance, to make sure that it will act as intended later on. In order to evaluate a machine learning performance, we need to use well-defined parameters and insights. To compute the different evaluation metrics, we need to use four important parameters:
- True positive
- False positive
- True negative
- False negative
The notations for the preceding parameters are as follows:
- tp: True positive
- fp: False positive
- tn: True negative
- fn: False negative
There are many machine learning evaluation metrics, such as the following:
- Precision: Precision, or positive predictive value, is the ratio of positive samples that are correctly classified divided by the total number of positive classified samples:
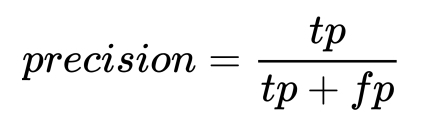
- Recall: Recall, or the true positive rate, is the ratio of true positive classifications divided by the total number of positive samples in the dataset:
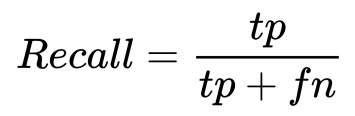
- F-Score: The F-score, or F-measure, is a measure that combines the precision and recall in one harmonic formula:
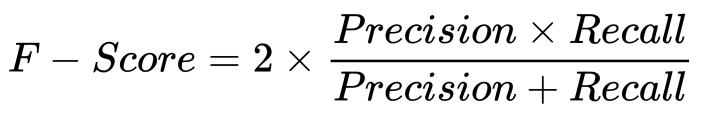
- Accuracy: Accuracy is the ratio of the total correctly classified samples divided by the total number of samples. This measure is not sufficient by itself, because it is used when we have an equal number of classes.
- Confusion matrix: The confusion matrix is a graphical representation of the performance of a given machine learning model. It summarizes the performance of each class in a classification problem.
Dimensionality reduction
Dimensionality reduction is used to reduce the dimensionality of a dataset. It is really helpful in cases where the problem becomes intractable, when the number of variables increases. By using the term dimensionality, we are referring to the features. One of the basic reduction techniques is feature engineering.
Generally, we have many dimensionality reduction algorithms:
- Low variance filter: Dropping variables that have low variance, compared to others.
- High correlation filter: This identifies the variables with high correlation, by using pearson or polychoric, and selects one of them using the Variance Inflation Factor (VIF).
- Backward feature elimination: This is done by computing the sum of square of error (SSE) after eliminating each variable n times.
- Linear Discriminant Analysis (LDA): This reduces the number of dimensions, n, from the original to the number of classes — 1 number of features.
- Principal Component Analysis (PCA): This is a statistical procedure that transforms variables into a new set of variables (principle components).
Improving classification with ensemble learning
In many cases, when you build a machine learning model, you receive low accuracy and low results. In order to get good results, we can use ensemble learning techniques. This can be done by combining many machine learning techniques into one predictive model.
We can categorize ensemble learning techniques into two categories:
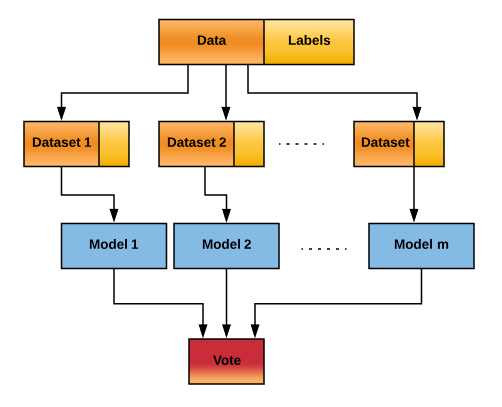
- Parallel ensemble methods—The following graph illustrates how parallel ensemble learning works:
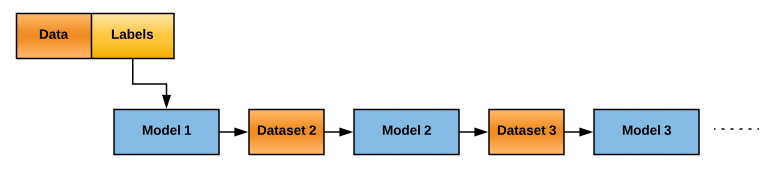
- Sequential ensemble methods—The following graph illustrates how sequential ensemble learning works:
The following are the three most used ensemble learning techniques:
- Bootstrap aggregating (bagging): This involves building separate models and combining them by using model averaging techniques, like weighted average and majority vote.
- Boosting: This is a sequential ensemble learning technique. Gradient boosting is one of the most used boosting techniques.
- Stacking: This is like boosting, but it uses a new model to combine submodels.






