






















































The following diagram shows how Spark applications run on a cluster. They are independent sets of processes that are coordinated by the SparkContext object in the Driver Program. SparkContext connects to a Cluster Manager, which is responsible for allocating resources across applications. Once the SparkContext is connected, Spark gets executors across cluster nodes.
Executors are processes that execute computations and store data for a given Spark application. SparkContext sends the application code (which could be a JAR file for Scala or .py files for Python) to the executors. Finally, it sends the tasks to run to the executors:
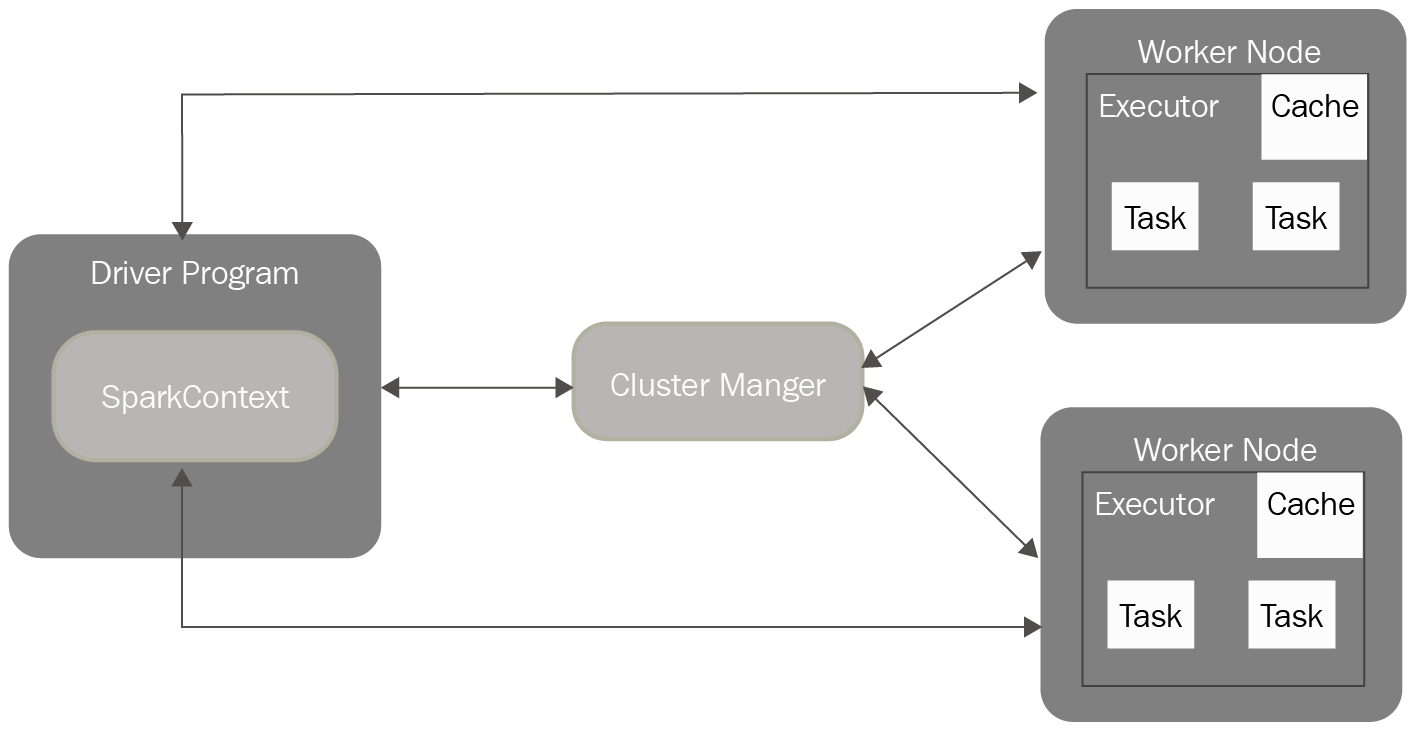
To isolate applications from each other, every Spark application receives its own executor processes. They stay alive for the duration of the whole application and run tasks in multithreading mode. The downside to this is that it isn't possible to share data across different Spark applications – to share it, data needs to be persisted to an external storage system.
Spark supports different cluster managers, but it is agnostic to the underlying type.
The driver program, at execution time, must be network addressable from the worker nodes because it has to listen for and accept incoming connections from its executors. Because it schedules tasks on the cluster, it should be executed close to the worker nodes, on the same local area network (if possible).
The following are the cluster managers that are currently supported in Spark:
- Standalone: A simple cluster manager that makes it easy to set up a cluster. It is included with Spark.
- Apache Mesos: An open source project that's used to manage computer clusters, and was developed at the University of California, Berkeley.
- Hadoop YARN: The resource manager available in Hadoop starting from release 2.
- Kubernetes: An open source platform for providing a container-centric infrastructure. Kubernetes support in Spark is still experimental, so it's probably not ready for production yet.











