






















































Simple Linear Regression
In Figure 2.3, you can see the crime rate per capita and the median value of owner-occupied homes for the city of Boston, which is the largest city of the Commonwealth of Massachusetts. We seek to use regression analysis to gain an insight into what drives crime rates in the city.
Such analysis is useful to policy makers and society in general because it can help with decision-making directed toward the reduction of the crime rate, and hopefully the eradication of crime across communities. This can make communities safer and increase the quality of life in society.
This is a data science problem and is of the supervised machine learning type. There is a dependent variable named crime rate (let's denote it Y), whose variation we seek to understand in terms of an independent variable, named Median value of owner-occupied homes (let's denote it X).
In other words, we are trying to understand the variation in crime rate based on different neighborhoods.
Regression analysis is about finding a function, under a given set of assumptions, that best describes the relationship between the dependent variable (Y in this case) and the independent variable (X in this case).
When the number of independent variables is only one, and the relationship between the dependent and the independent variable is assumed to be a straight line, as shown in Figure 2.3, this type of regression analysis is called simple linear regression. The straight-line relationship is called the regression line or the line of best fit:
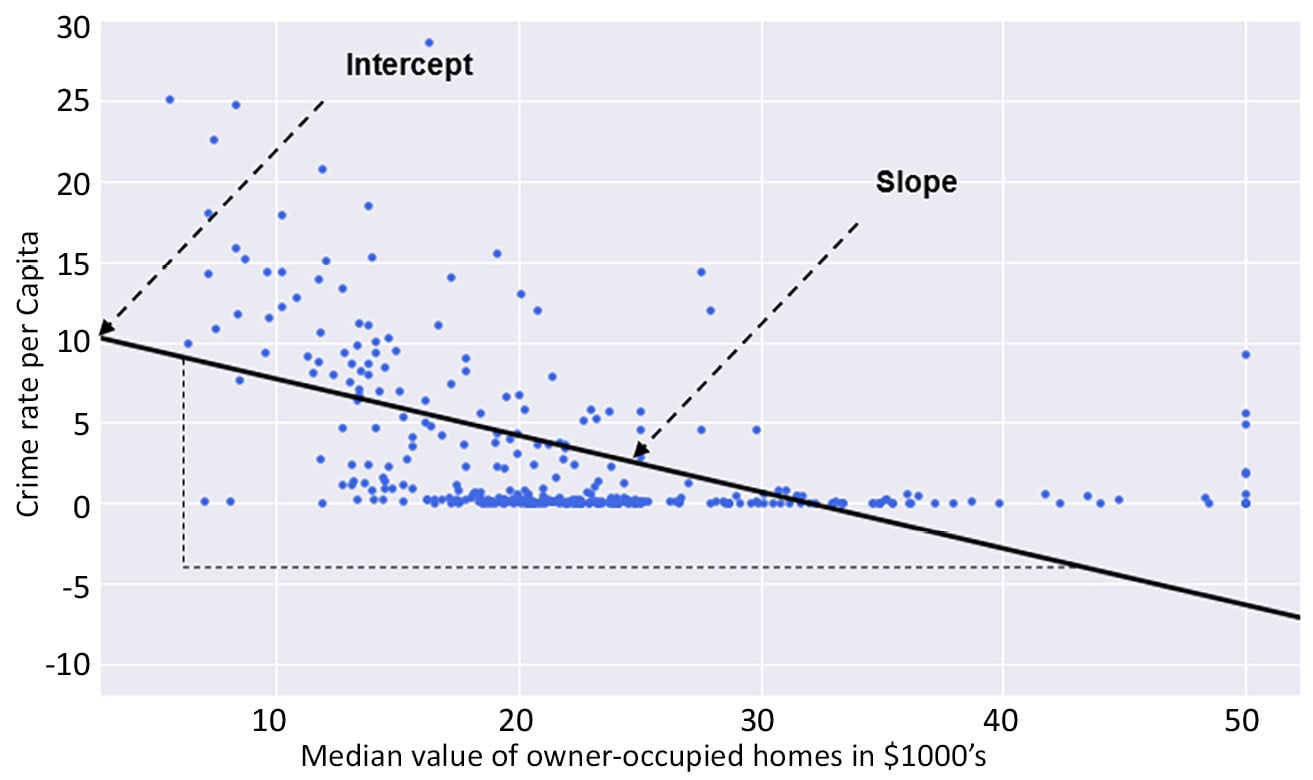
Figure 2.3: A scatter plot of the crime rate against the median value of owner-occupied homes
In Figure 2.3, the regression line is shown as a solid black line. Ignoring the poor quality of the fit of the regression line to the data in the figure, we can see a decline in crime rate per capita as the median value of owner-occupied homes increases.
From a data science point of view, this observation may pose lots of questions. For instance, what is driving the decline in crime rate per capita as the median value of owner-occupier homes increases? Are richer suburbs and towns receiving more policing resources than less fortunate suburbs and towns? Unfortunately, these questions cannot be answered with such a simple plot as we find in Figure 2.3. But the observed trend may serve as a starting point for a discussion to review the distribution of police and community-wide security resources.
Returning to the question of how well the regression line fits the data, it is evident that almost one-third of the regression line has no data points scattered around it at all. Many data points are simply clustered on the horizontal axis around the zero (0) crime rate mark. This is not what you expect of a good regression line that fits the data well. A good regression line that fits the data well must sit amidst a cloud of data points.
It appears that the relationship between the crime rate per capita and the median value of owner-occupied homes is not as linear as you may have thought initially.
In this chapter, we will learn how to use the logarithm function (a mathematical function for transforming values) to linearize the relationship between the crime rate per capita and the median value of owner-occupied homes, in order to improve the fit of the regression line to the data points on the scatter graph.
We have ignored a very important question thus far. That is, how can you determine the regression line for a given set of data?
A common method used to determine the regression line is called the method of least squares, which is covered in the next section.
The Method of Least Squares
The simple linear regression line is generally of the form shown in Figure 2.4, where β0 and β1 are unknown constants, representing the intercept and the slope of the regression line, respectively.
The intercept is the value of the dependent variable (Y) when the independent variable (X) has a value of zero (0). The slope is a measure of the rate at which the dependent variable (Y) changes when the independent variable (X) changes by one (1). The unknown constants are called the model coefficients or parameters. This form of the regression line is sometimes known as the population regression line, and, as a probabilistic model, it fits the dataset approximately, hence the use of the symbol (≈) in Figure 2.4. The model is called probabilistic because it does not model all the variability in the dependent variable (Y) :
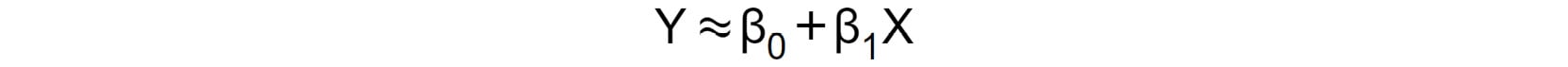
Figure 2.4: Simple linear regression equation
Calculating the difference between the actual dependent variable value and the predicted dependent variable value gives an error that is commonly termed as the residual (ϵi).
Repeating this calculation for every data point in the sample, the residual (ϵi) for every data point can be squared, to eliminate algebraic signs, and added together to obtain the error sum of squares (ESS).
The least squares method seeks to minimize the ESS.




