






















































Making use of the recorder
As you saw in the previous chapter, the PAD designer window allows us not only to drag and drop actions onto the design canvas but also allows us to record a UI flow. This concept is comparable to a screen recorder that records every step, every mouse click, and keyboard stroke to play back this sequence the same way later.
We want to use this functionality once to create an overview of all book titles of the PacktPub publisher so that we can use this information elsewhere – for example, in a database. Unfortunately, we don’t have direct access to PacktPub’s underlying source, but we can get the book titles via their website at https://subscription.packtpub.com/search. However, we don’t want to highlight every single title on the website and then copy and paste them into another tool. That would take a very long time and also be quite boring. PAD can do this job for us.
In the following example, we will use a concept known as web scraping – that is, structurally extracting information from web pages. Note this also works with numerous other websites, so this technique can be used universally. However, the prerequisite for using this method is that we must install and activate a small extension for the browser we’re using so that PAD can access the elements of a web page. So, let’s get started:
- Create a new flow and give it a meaningful name, such as Web Scraping PacktPub.
- Locate the Browser automation actions group in the actions pane and expand it. You will see a Launch new... action for each of the browsers from Google, Firefox, and Microsoft Edge. I have Microsoft Edge installed on my machine, so I will click and drag this action onto the canvas:
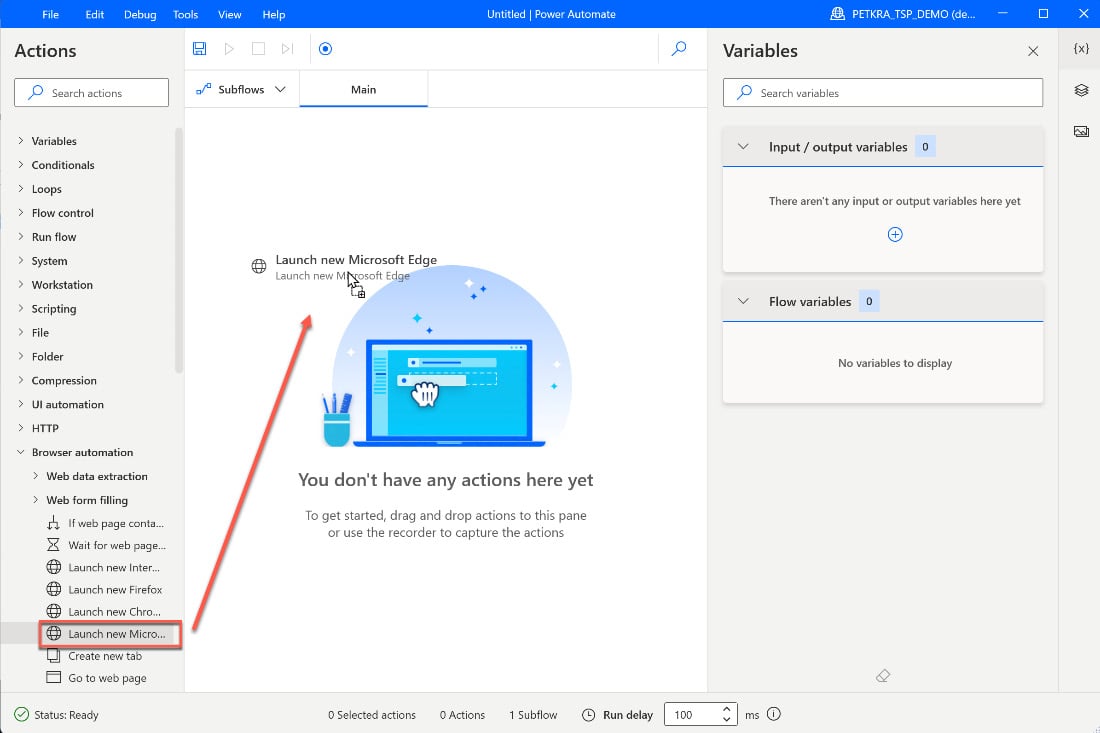
Figure 2.24 – Dragging the browser action onto the canvas
- At this point, you might be requested to install the browser extension for PAD:
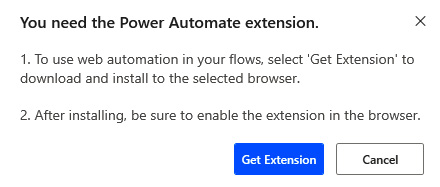
Figure 2.25 – Browser extension installation dialog
- This will only happen once. Get the extension and make sure that it is activated.
In the dialog for this action, enter the data accordingly and make sure that you use https://subscription.packtpub.com/search as the initial URL. Click on the Save button:
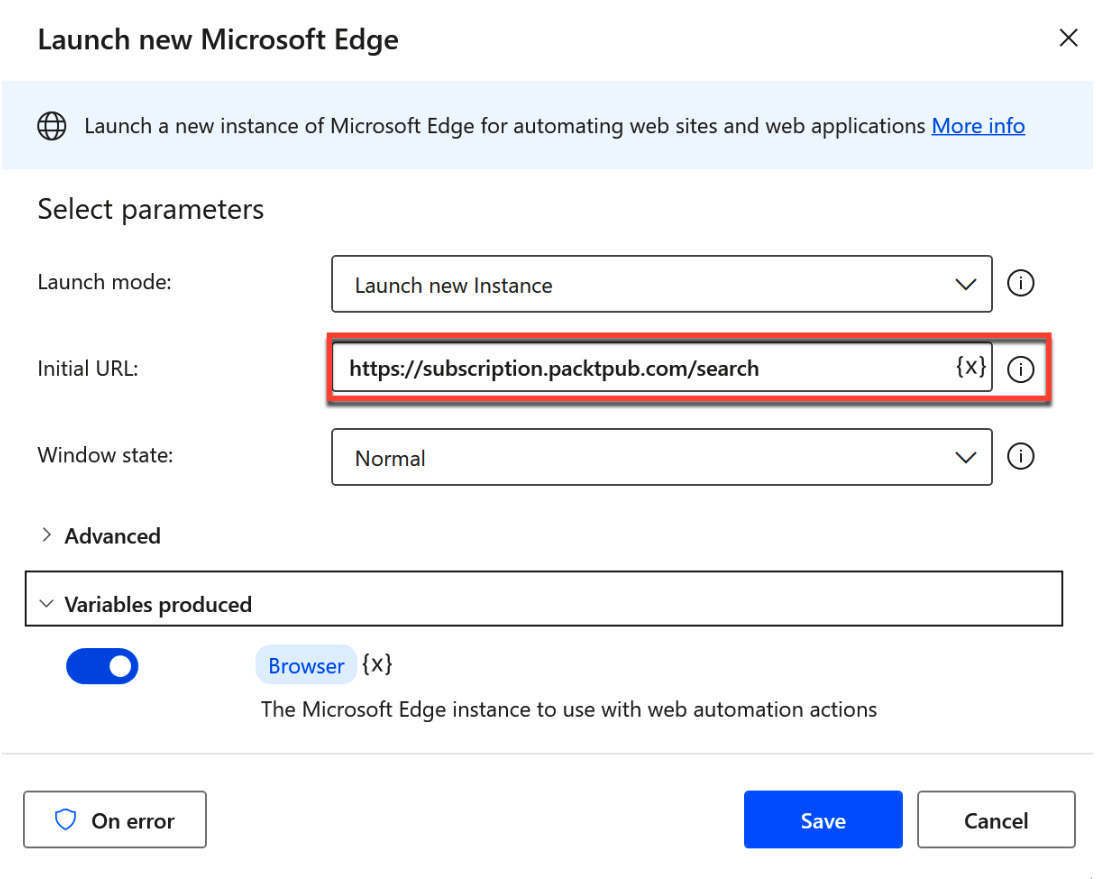
Figure 2.26 – Settings for the browser launch action
You should now have one action in the canvas that opens the website mentioned previously in a new browser instance. Test this flow now by pressing the Run button above the design canvas and leave the browser window open for now.
As mentioned previously, we can always add more functionalities to the flow. For this, we will use the recorder. With the browser window open, switch back to the design canvas/workspace window and click the Recorder button:
Figure 2.27 – The recorder button
At this point, the PAD designer will disappear, and a smaller recorder window will appear instead. It should look like this:
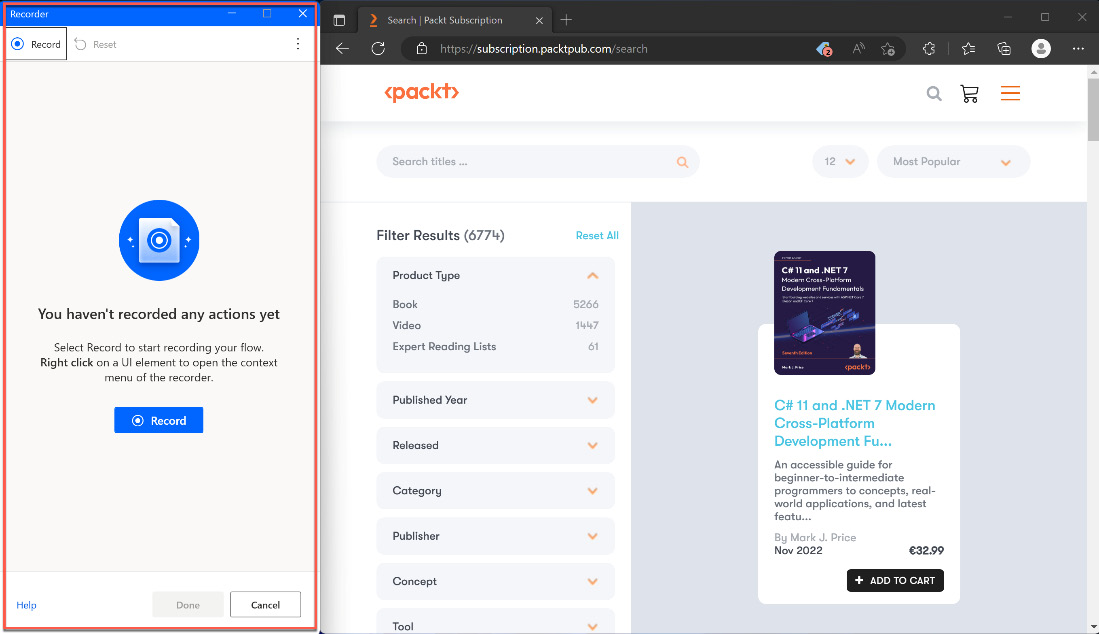
Figure 2.28 – The recorder window
Now, the funny part begins. Start the recording by either clicking the button in the middle of the screen or at the top. The recorder window will change and display an empty area under Recorded actions. Use your mouse and hover over different elements on the website, such as the book picture. You will see that PAD tries to identify the different elements on the website and frames them accordingly. In the following screenshot, I hovered over the book image:
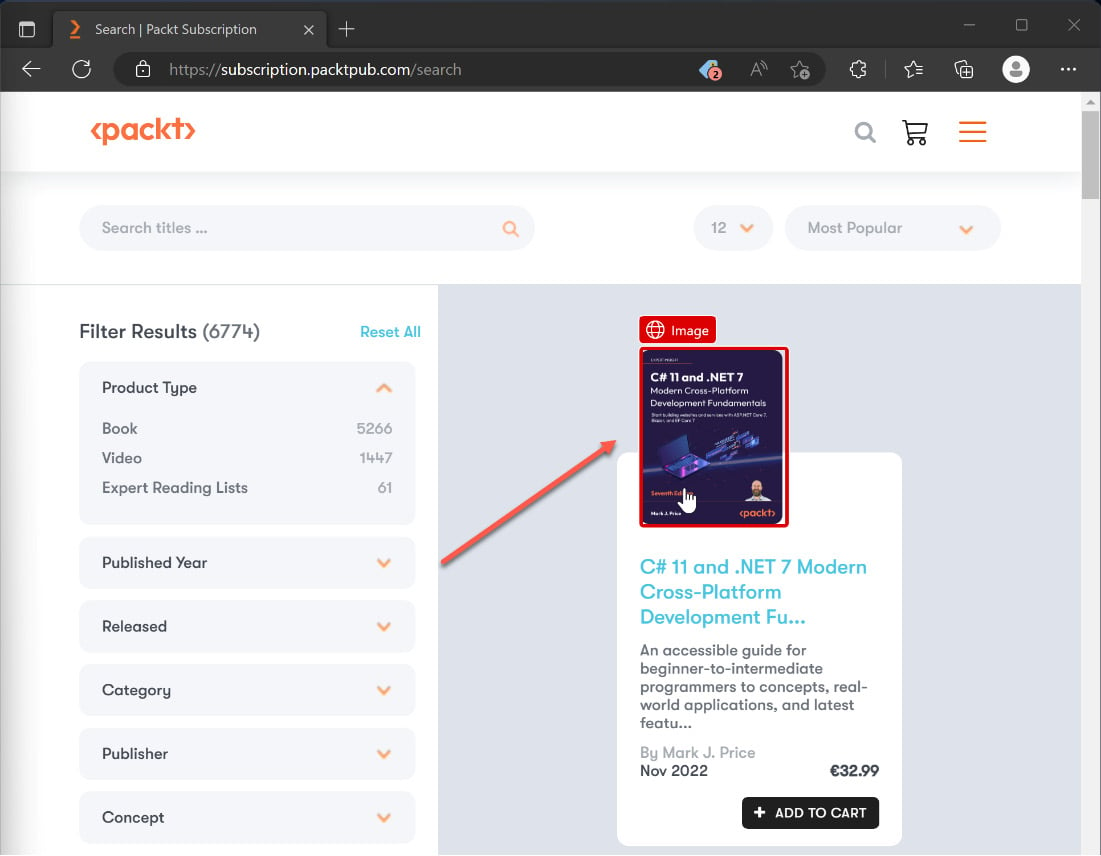
Figure 2.29 – Detecting web elements
For the recorder to recognize the web page elements correctly, it sometimes takes a bit of dexterity. It also helps to move the mouse out of the desired area and back in again to get the right mark. Once the correct element has been highlighted, click the right mouse button to be able to select the information we want to extract from this element. A context menu for this element will appear so that we can select different entries:
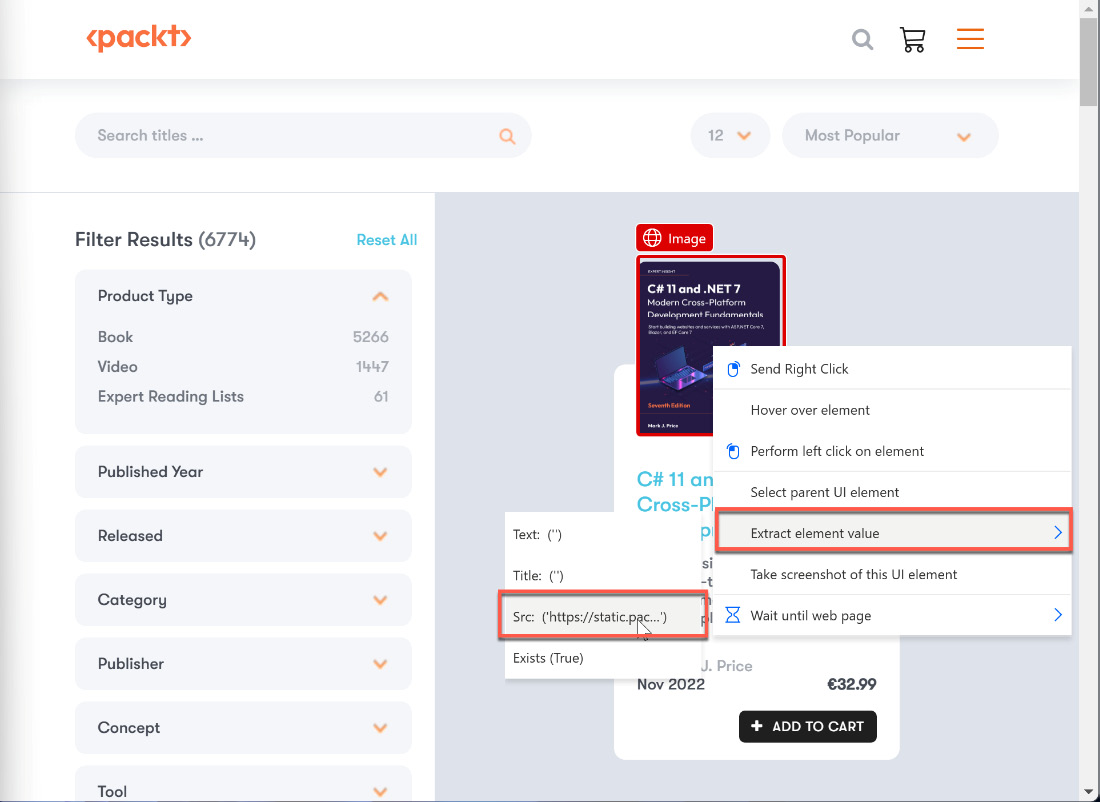
Figure 2.30 – Context menu for web elements
Let’s take a look at this in more detail:
- Extract element value: This allows us to extract information from this element. A web element can always have different properties, such as Text or Title.
- Wait until web page: This allows us to wait for specific events on the page, such as when an element contains a text or gets visible.
- Take screenshot of this UI element: This takes a screenshot and stores it in PAD flow.
In our case, we may want to extract the information of the image source, so we will choose Extract element value | Src. The recorder window should look like this now:
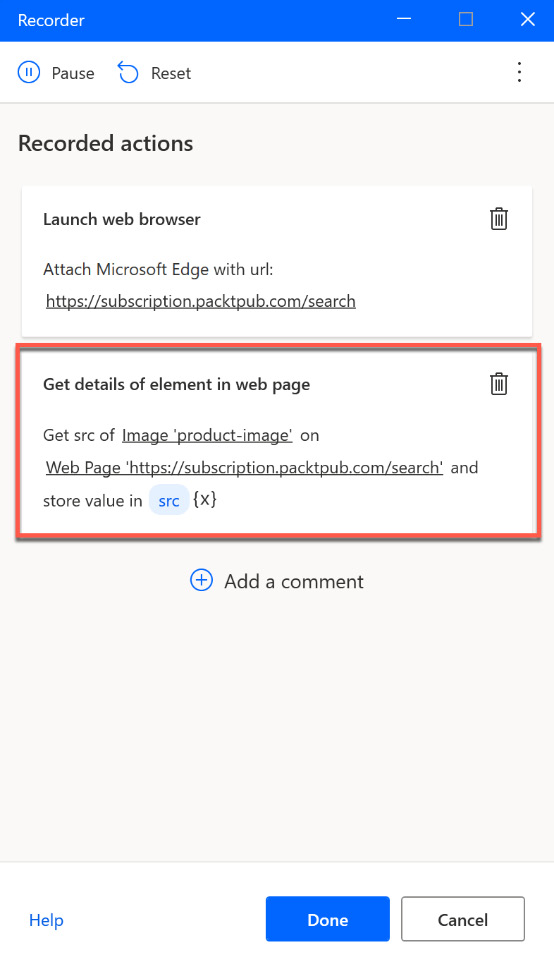
Figure 2.31 – A recorded action in the recorder
Important note – remove additional actions
You might have other actions that have been recorded by the recorder, depending on where you clicked and what keys you might have pressed. For our example, there must be only one action in the recorder. Use the Delete button (trashcan symbol) to remove any additional actions.
Now, repeat the same process for the title of the book. Use your mouse to hover over the elements and the title and click the right mouse button:
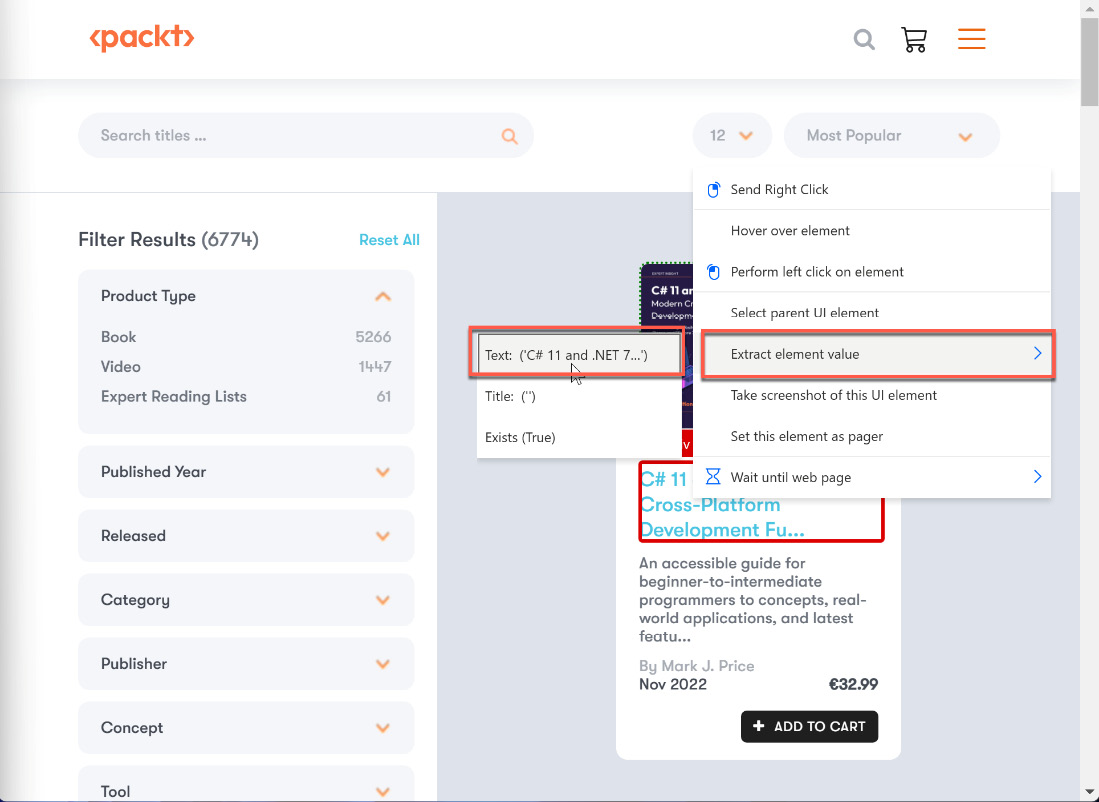
Figure 2.32 – Extracting data from a web element
This time, we want to extract the title of the element. With that, we have captured two elements on the web page, which are represented in the recorder window like this:
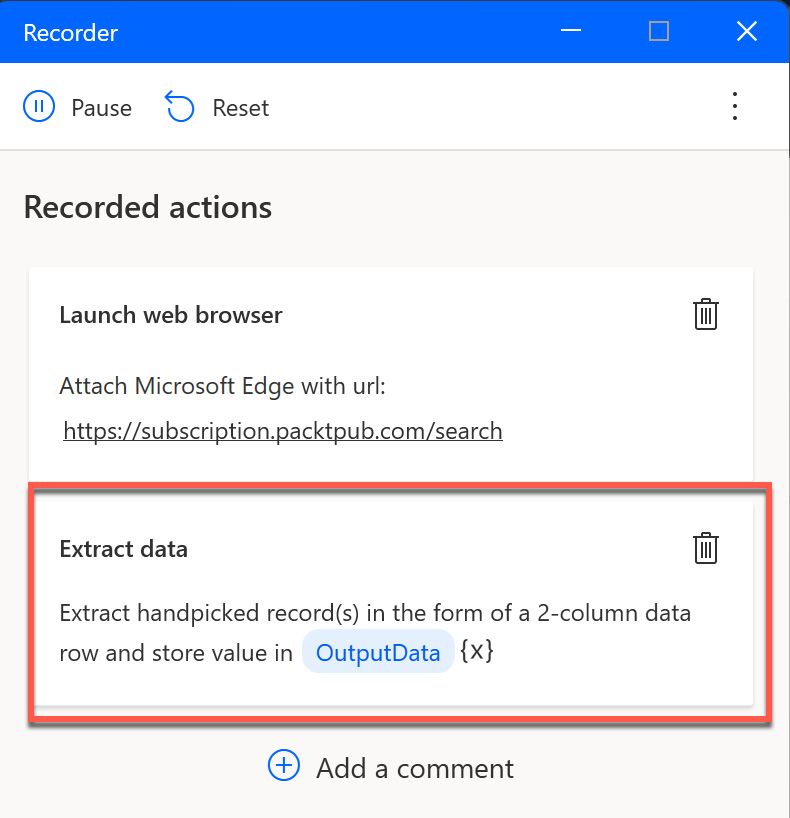
Figure 2.33 – Extracted data in the recorder
There is an important difference here: PAD already recognized that we captured two pieces of information from one record on the web page. Our next step will be to go to the next element, and this is where some magic starts. If you repeat the first step and mark the next book image and extract the Src information again, PAD will recognize this pattern and assume that you want to do the same as with the first element. We can see this on the web page because PAD has marked the corresponding elements with a green dotted line:
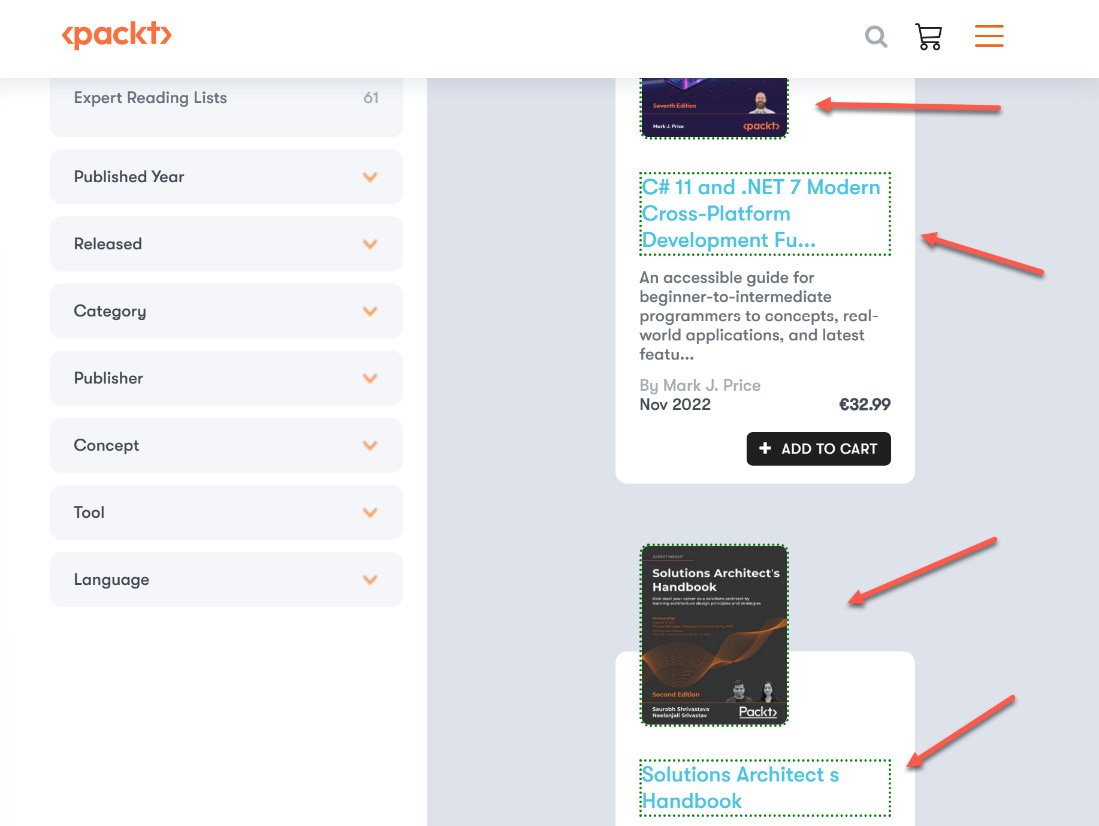
Figure 2.34 – Pattern recognition of the recorder
Pattern recognition
Please notice that it sometimes takes capturing more than two structures before the recorder recognizes the pattern. So, please proceed to the next element if PAD does not recognize the pattern immediately. Recognition also depends on the underlying structure of the HTML. After the third or fourth element at the latest, the pattern will be recognized.
This means that PAD will capture all the elements on this page now. But what about the next page of books? Let’s scroll down so that we can see the pagination control on that website:
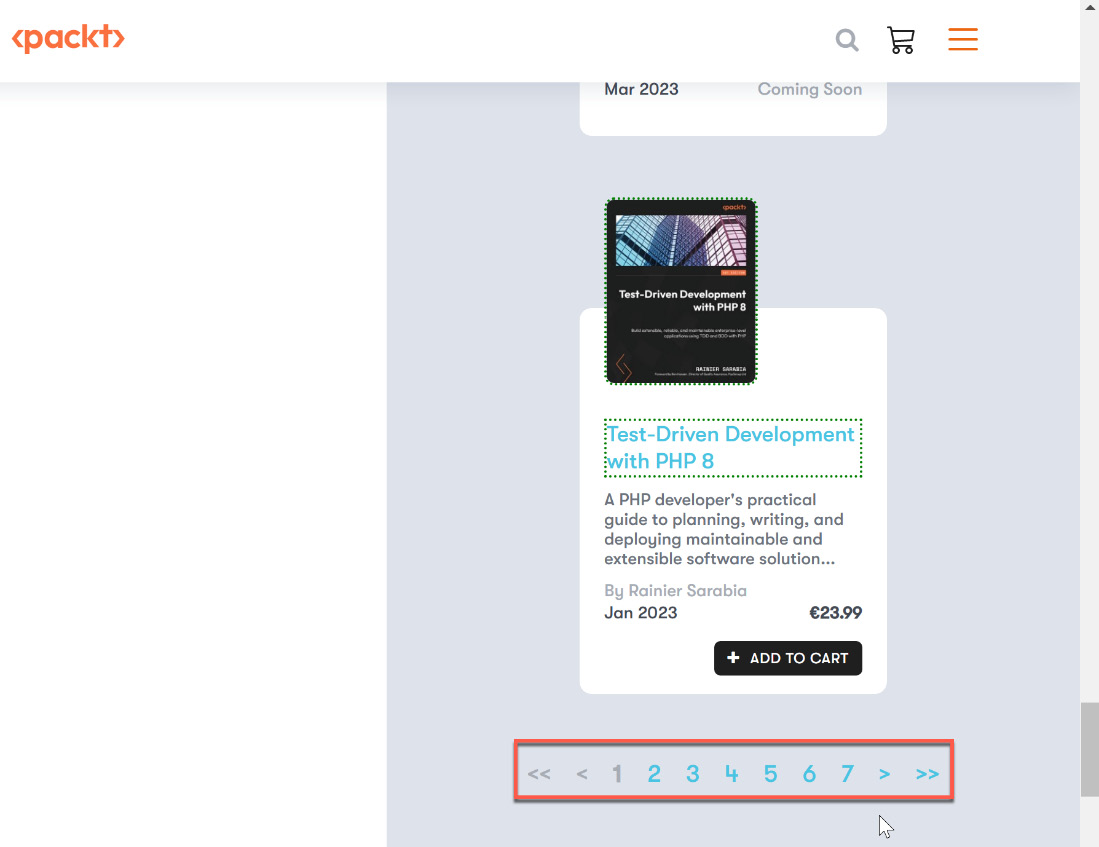
Figure 2.35 – Incorporating navigation
We can now use the single arrow button to load the next page. Right-click on the element shown in the following screenshot and choose Set this element as pager:
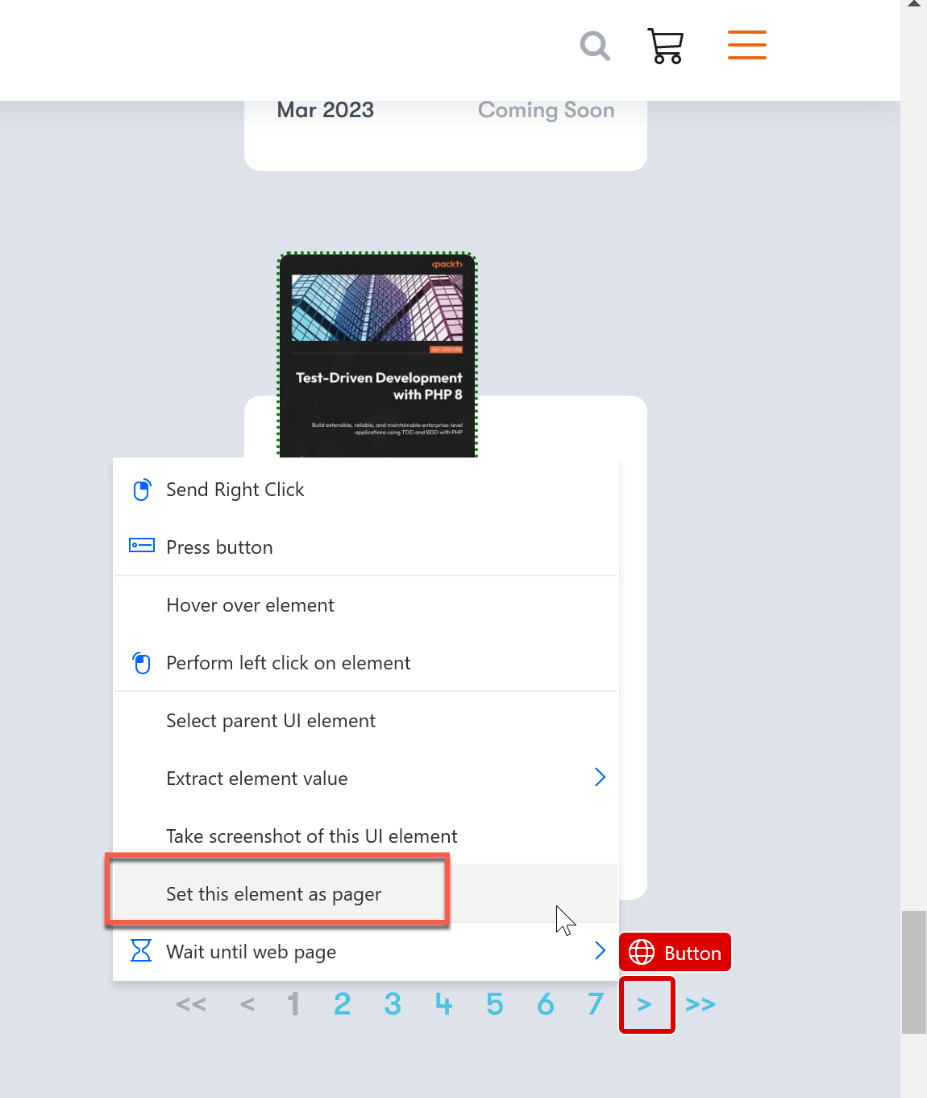
Figure 2.36 – Using a pager in a recording
The element now gets a little blue dotted border, indicating the pager functionality. Looking at the recorder window, just one element should be seen here:
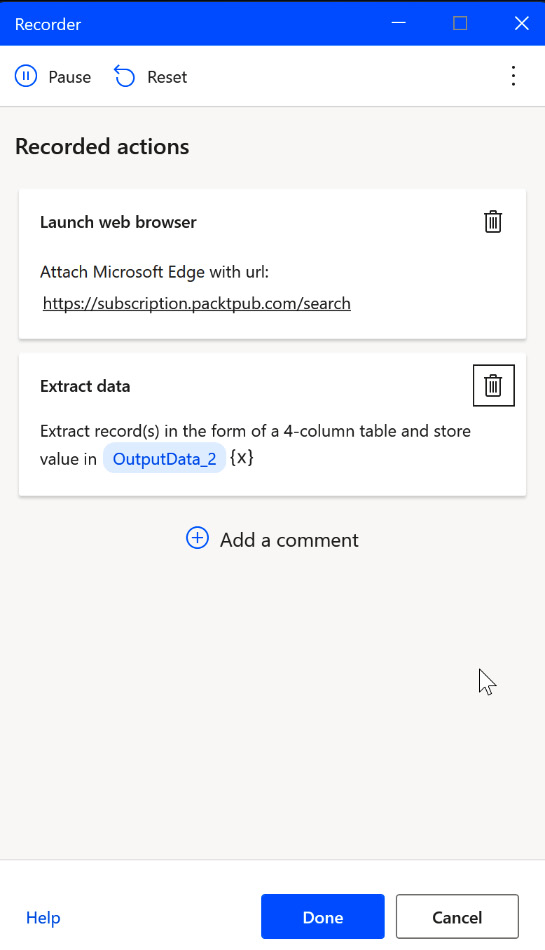
Figure 2.37 – Recorded web scraping actions
If other elements have been captured by mistake, just delete them. You can now stop the recording by clicking the Done button. Now, the recorded actions get transferred to the main PAD design window:
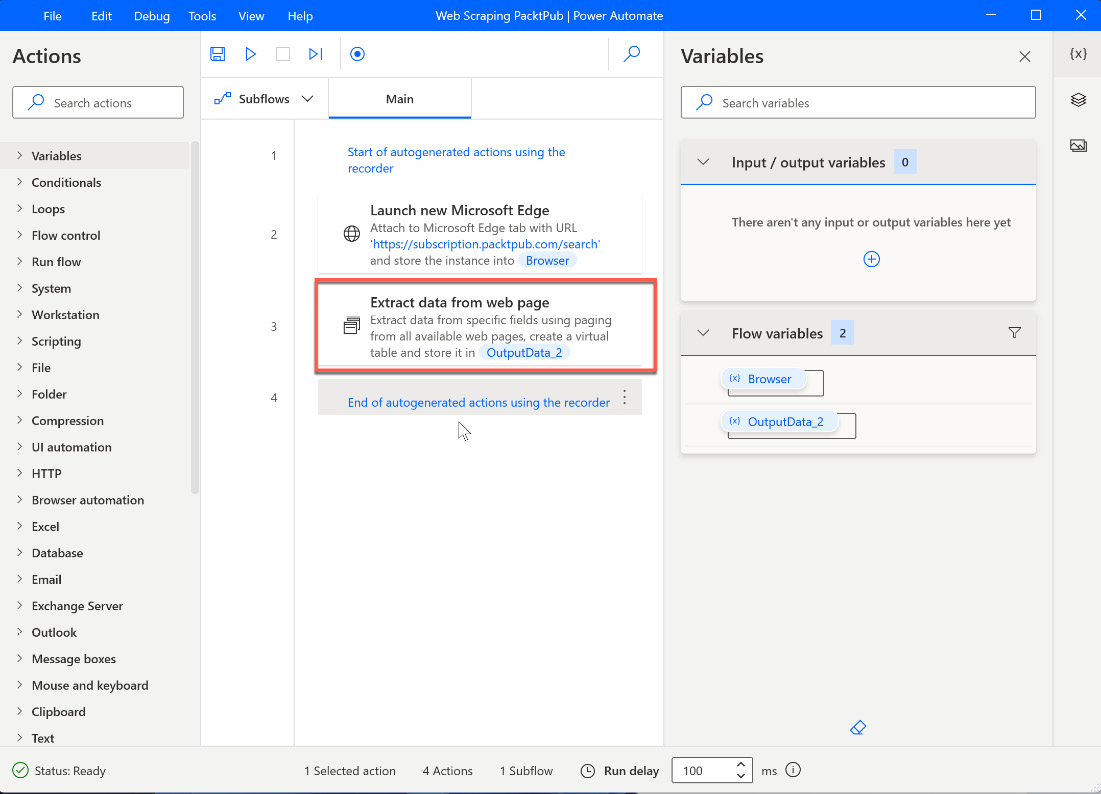
Figure 2.38 – Transferring recorded actions to the designer
There are also comments in the list of actions describing the start and end of the generated actions by the recorder. Let’s investigate the Extract data from web page action a bit more by double-clicking it:
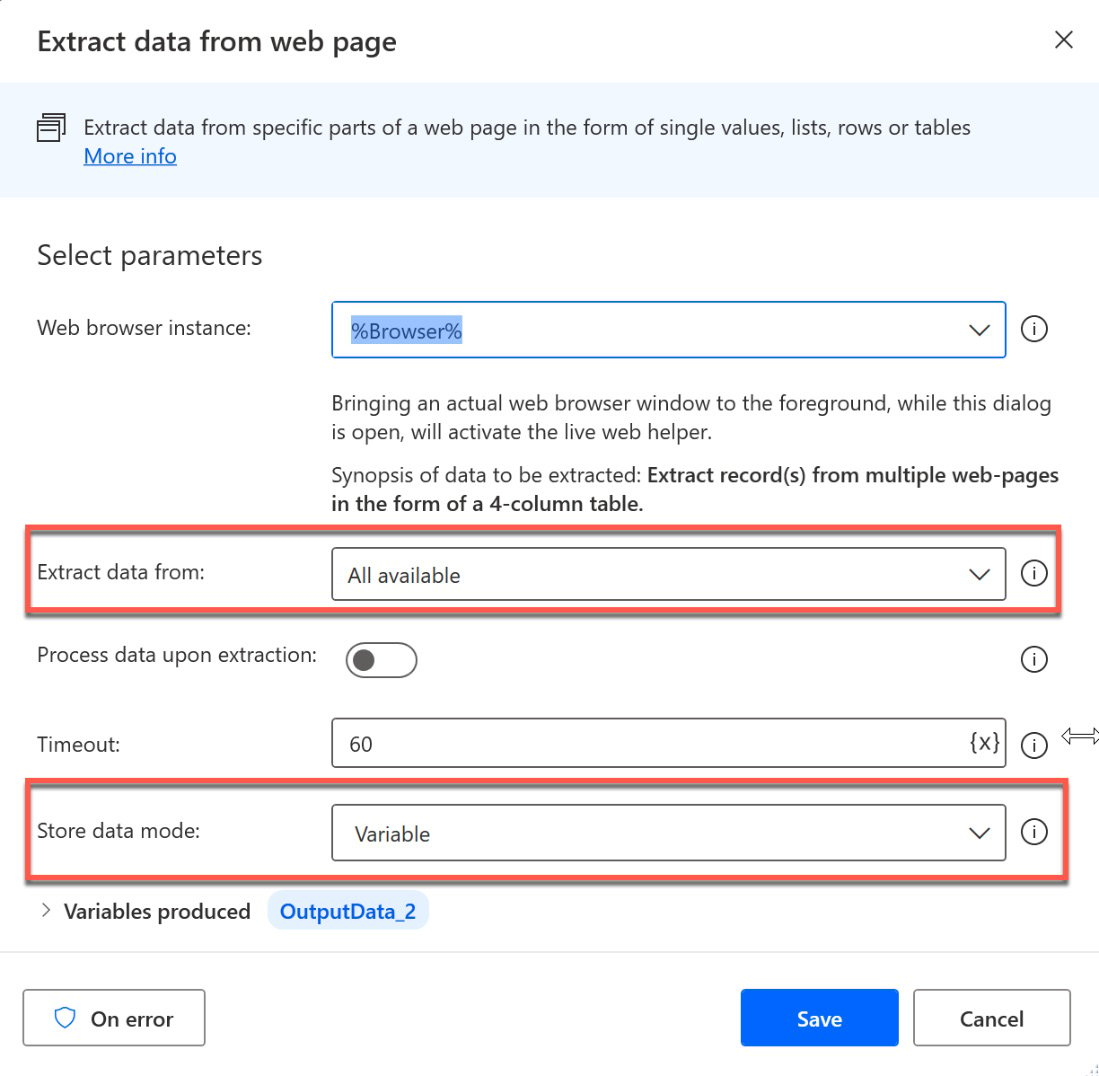
Figure 2.39 – Revealing the web data extraction
The interesting parts here are Extract data from and Store data mode. After the browser has been loaded by our first action in the flow, this action extracts all the data from the web page unless we don’t tell it otherwise. While on some occasions this might be useful, for our test, we only want to extract the first 10 pages. Click on the dropdown for the All available entry and change this to Only the first. Now, another text box will appear, where we can enter the number of web pages to process.
The last setting for this example is Store data mode. So far, the data that is captured is stored in a variable (DataFromWebPage, in my example). But of course, there are other ways to work with this data now. For example, you could take this variable and use it as input for another action after the web data has been extracted, or you could choose to store this in Excel. Therefore, click the dropdown for Store data mode and change the value from Variable to Excel spreadsheet:
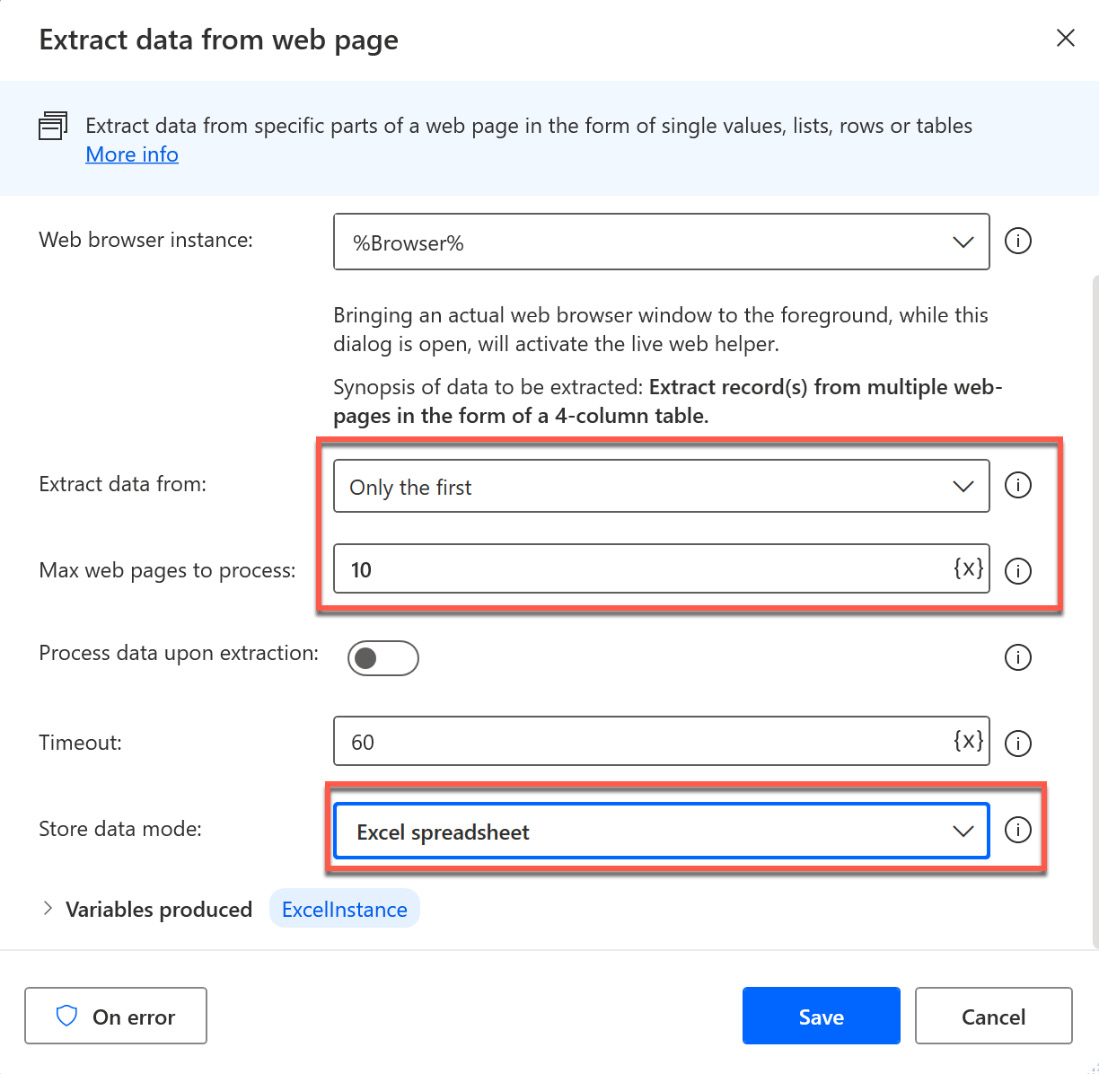
Figure 2.40 – Modifying the web data extraction parameters
Now, the web data extraction will only run for the first 10 pages, take the data, launch Excel with a new spreadsheet, and paste the captured data in there. Save the dialog now and let the show begin. On my machine, it took 45 seconds to extract 120 records and paste them into Excel.


