We are now prepared to see a very standard example for parallel computing that we will revisit later in this text—an algorithm to generate an image of the Mandelbrot set. Let's first define exactly what we mean.
For a given complex number, c, we define a recursive sequence for 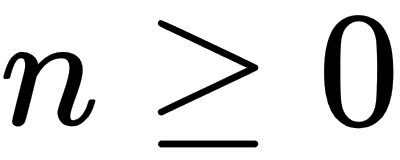 , with
, with 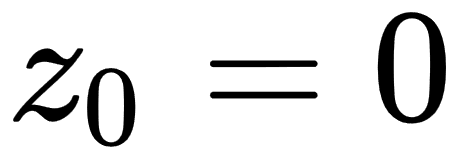 and
and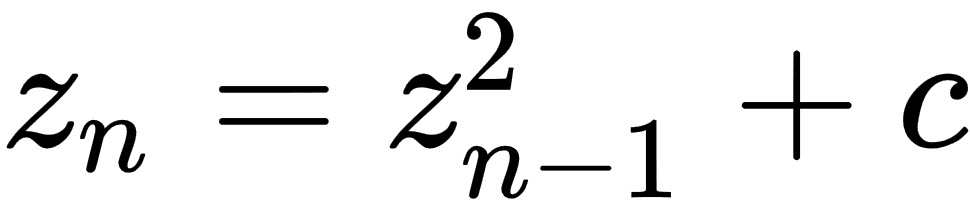 for
for 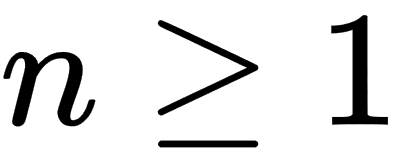 . If |zn| remains bounded by 2 as n increases to infinity, then we will say that c is a member of the Mandelbrot set.
. If |zn| remains bounded by 2 as n increases to infinity, then we will say that c is a member of the Mandelbrot set.
Recall that we can visualize the complex numbers as residing on a two-dimensional Cartesian plane, with the x-axis representing the real components and the y-axis representing the imaginary components. We can therefore easily visualize the Mandelbrot set with a very appealing (and well-known) graph. Here, we will represent members of the Mandelbrot set with a lighter shade, and nonmembers with a darker shade on the complex Cartesian plane as follows:
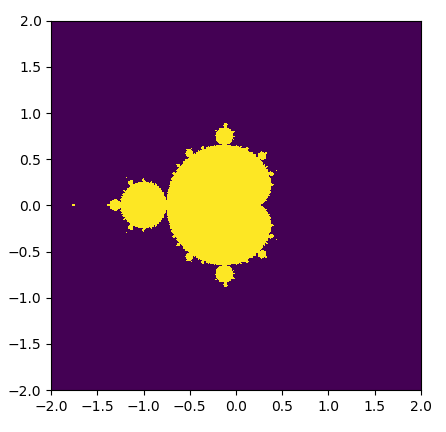
Now, let's think about how we would go about generating this set in Python. We have to consider a few things first—since we obviously can't check whether every single complex number is in the Mandelbrot set, we have to choose a certain range to check over; we have to determine how many points in each range we will consider (width, height); and the maximum value of n that we will check |zn| for (max_iters). We can now prepare to implement a function to generate a graph of the Mandelbrot set—here, we do this by iterating over every single point in the graph in serial.
We will start by importing the NumPy library, which is a numerical library that we will be making ample use of throughout this text. Our implementation here is in the simple_mandelbrot function. We start by using NumPy's linspace function to generate a lattice that will act as a discrete complex plane (the rest of the code that follows should be fairly straightforward):
import numpy as np
def simple_mandelbrot(width, height, real_low, real_high, imag_low, imag_high, max_iters):
real_vals = np.linspace(real_low, real_high, width)
imag_vals = np.linspace(imag_low, imag_high, height)
# we will represent members as 1, non-members as 0.
mandelbrot_graph = np.ones((height,width), dtype=np.float32)
for x in range(width):
for y in range(height):
c = np.complex64( real_vals[x] + imag_vals[y] * 1j )
z = np.complex64(0)
for i in range(max_iters):
z = z**2 + c
if(np.abs(z) > 2):
mandelbrot_graph[y,x] = 0
break
return mandelbrot_graph
Now, we want to add some code to dump the image of the Mandelbrot set to a PNG format file, so let's add the appropriate headers at the beginning:
from time import time
import matplotlib
# the following will prevent the figure from popping up
matplotlib.use('Agg')
from matplotlib import pyplot as plt
Now, let's add some code to generate the Mandelbrot set and dump it to a file, and use the time function to time both operations:
if __name__ == '__main__':
t1 = time()
mandel = simple_mandelbrot(512,512,-2,2,-2,2,256, 2)
t2 = time()
mandel_time = t2 - t1
t1 = time()
fig = plt.figure(1)
plt.imshow(mandel, extent=(-2, 2, -2, 2))
plt.savefig('mandelbrot.png', dpi=fig.dpi)
t2 = time()
dump_time = t2 - t1
print 'It took {} seconds to calculate the Mandelbrot graph.'.format(mandel_time)
print 'It took {} seconds to dump the image.'.format(dump_time)
Now let's run this program (this is also available as the mandelbrot0.py file, in folder 1, within the GitHub repository):
It took about 14.62 seconds to generate the Mandelbrot set, and about 0.11 seconds to dump the image. As we have seen, we generate the Mandelbrot set point by point; there is no interdependence between the values of different points, and it is, therefore, an intrinsically parallelizable function. In contrast, the code to dump the image cannot be parallelized.
Now, let's analyze this in terms of Amdahl's Law. What sort of speedups can we get if we parallelize our code here? In total, both pieces of the program took about 14.73 seconds to run; since we can parallelize the Mandelbrot set generation, we can say that the portion of execution time for parallelizable code is p = 14.62 / 14.73 = .99. This program is 99% parallelizable!
What sort of speedup can we potentially get? Well, I'm currently working on a laptop with an entry-level GTX 1050 GPU with 640 cores; our N will thus be 640 when we use the formula. We calculate the speedup as follows:
That is definitely very good and would indicate to us that it is worth our effort to program our algorithm to use the GPU. Keep in mind that Amdahl's Law only gives a very rough estimate! There will be additional considerations that will come into play when we offload computations onto the GPU, such as the additional time it takes for the CPU to send and receive data to and from the GPU; or the fact that algorithms that are offloaded to the GPU are only partially parallelizable.

 Germany
Germany
 Slovakia
Slovakia
 Canada
Canada
 Brazil
Brazil
 Singapore
Singapore
 Hungary
Hungary
 Philippines
Philippines
 Mexico
Mexico
 Thailand
Thailand
 Ukraine
Ukraine
 Luxembourg
Luxembourg
 Estonia
Estonia
 Lithuania
Lithuania
 Norway
Norway
 Chile
Chile
 United States
United States
 Great Britain
Great Britain
 India
India
 Spain
Spain
 South Korea
South Korea
 Ecuador
Ecuador
 Colombia
Colombia
 Taiwan
Taiwan
 Switzerland
Switzerland
 Indonesia
Indonesia
 Cyprus
Cyprus
 Denmark
Denmark
 Finland
Finland
 Poland
Poland
 Malta
Malta
 Czechia
Czechia
 New Zealand
New Zealand
 Austria
Austria
 Turkey
Turkey
 France
France
 Sweden
Sweden
 Italy
Italy
 Egypt
Egypt
 Belgium
Belgium
 Portugal
Portugal
 Slovenia
Slovenia
 Ireland
Ireland
 Romania
Romania
 Greece
Greece
 Argentina
Argentina
 Malaysia
Malaysia
 South Africa
South Africa
 Netherlands
Netherlands
 Bulgaria
Bulgaria
 Latvia
Latvia
 Australia
Australia
 Japan
Japan
 Russia
Russia





















