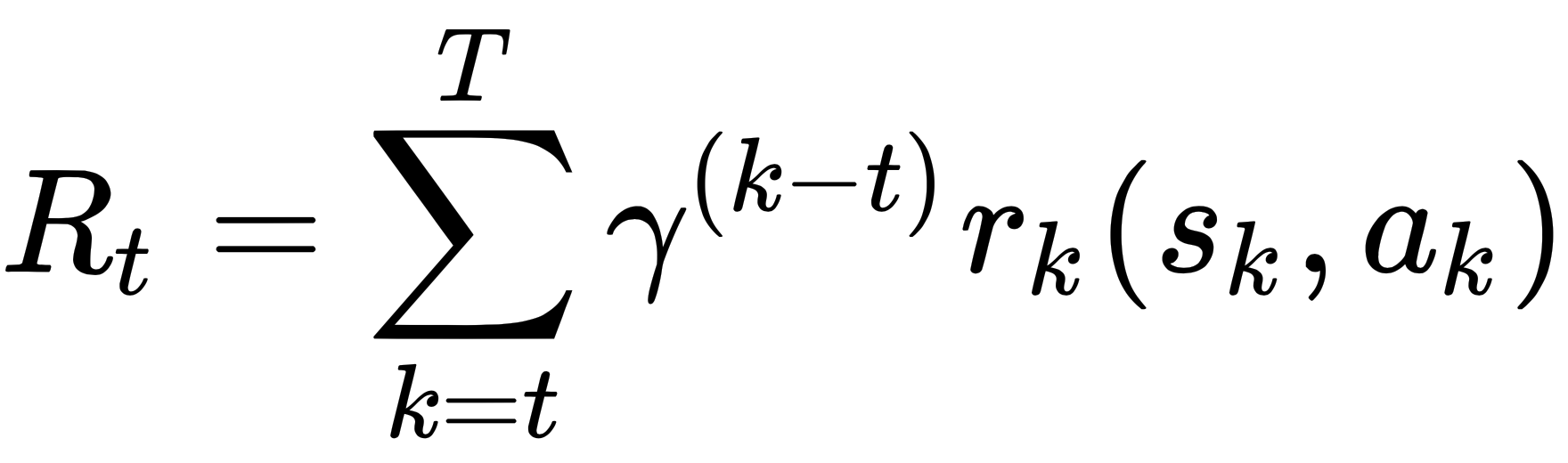Rewards in RL are no different from real world rewards – we all receive good rewards for doing well, and bad rewards (aka penalties) for inferior performance. Reward functions are provided by the environment to guide an agent to learn as it explores the environment. Specifically, it is a measure of how well the agent is performing.
The reward function defines what the good and bad things are that can happen to the agent. For instance, a mobile robot that reaches its goal is rewarded, but is penalized for crashing into obstacles. Likewise, an industrial robot arm is rewarded for putting a peg into a hole, but is penalized for being in undesired poses that can be catastrophic by causing ruptures or crashes. Reward functions are the signal to the agent regarding what is optimum and what isn't. The agent's long-term goal is to maximize rewards and minimize penalties.