






















































Time Series Analysis
In this section, we perform a time series analysis on the rides columns (registered and casual) in the bike sharing dataset.
A time series is a sequence of observations equally spaced in time and in chronological order. Typical examples of time series are stock prices, yearly rainfall, or the number of customers using a specific transportation service every day. When observing time series their fluctuation might result in random values, but, often, they exhibit certain patterns (for example, the highs and lows of ocean tides or hotel prices in the proximity of fares).
When studying time series, an important concept is the notion of stationarity. A time series is said to be strongly stationary if all aspects of its behavior do not change in time. In other words, given a time series, {Yt}(t≥0) , for each m and n, the distributions of Y1,…,Yn and Y(m+1),…,Y(m+n) are the same. In practice, strong stationarity is quite a restrictive assumption and, in most of the cases, not satisfied. Furthermore, for most of the methods illustrated later in this section to work, it is enough to have a time series that is weakly stationary, that is, its mean, standard deviation, and covariance are stationary with respect to time. More precisely, given {Yt}(t ≥ 0), we can observe:
E(Yi)=μ(a constant) for everyiVar(Yi)=σ^2(a constant) for everyiCorr(Yi,Yj)=ρ(i-j)for everyiandjand some function ρ(h)
In order to check stationarity in practice, we can rely on two different techniques for identifying time series stationarity: rolling statistics and augmented Dickey-Fuller stationarity test (in most cases, we consider both of them).
Rolling statistics is a practical method in which we plot the rolling mean and standard deviation of a time series and visually identify whether those values fluctuate around a constant one, without large deviations. We have to inform the reader that this is more a rule-of-thumb approach and not a rigorous statistical test for stationarity.
Augmented Dickey-Fuller stationarity test is a statistical test in which the null hypothesis is that the time series is nonstationary. Hence, when performing the test, a small p-value would be strong evidence against the time series being nonstationary.
Note
Since providing a detailed introduction to the augmented Dickey-Fuller test is out of the scope of this book, we refer the interested reader to the original book, Fuller, W. A. (1976). Introduction to Statistical Time Series. New York: John Wiley and Sons. ISBN 0-471-28715-6.
In practice, we rely on both of the techniques, as plotting the rolling statistics is not a rigorous approach. Let's define a utility function, which will perform both tests for us:
"""
define function for plotting rolling statistics and ADF test for time series
"""
from statsmodels.tsa.stattools import adfuller
def test_stationarity(ts, window=10, **kwargs):
# create dataframe for plotting
plot_data = pd.DataFrame(ts)
plot_data['rolling_mean'] = ts.rolling(window).mean()
plot_data['rolling_std'] = ts.rolling(window).std()
# compute p-value of Dickey-Fuller test
p_val = adfuller(ts)[1]
ax = plot_data.plot(**kwargs)
ax.set_title(f"Dickey-Fuller p-value: {p_val:.3f}")
We also need to extract the daily registered and casual rides from our preprocessed data:
# get daily rides
daily_rides = preprocessed_data[["dteday", "registered", \
"casual"]]
daily_rides = daily_rides.groupby("dteday").sum()
# convert index to DateTime object
daily_rides.index = pd.to_datetime(daily_rides.index)
Applying the previously defined test_stationarity() function to the daily rides produces the following plots:
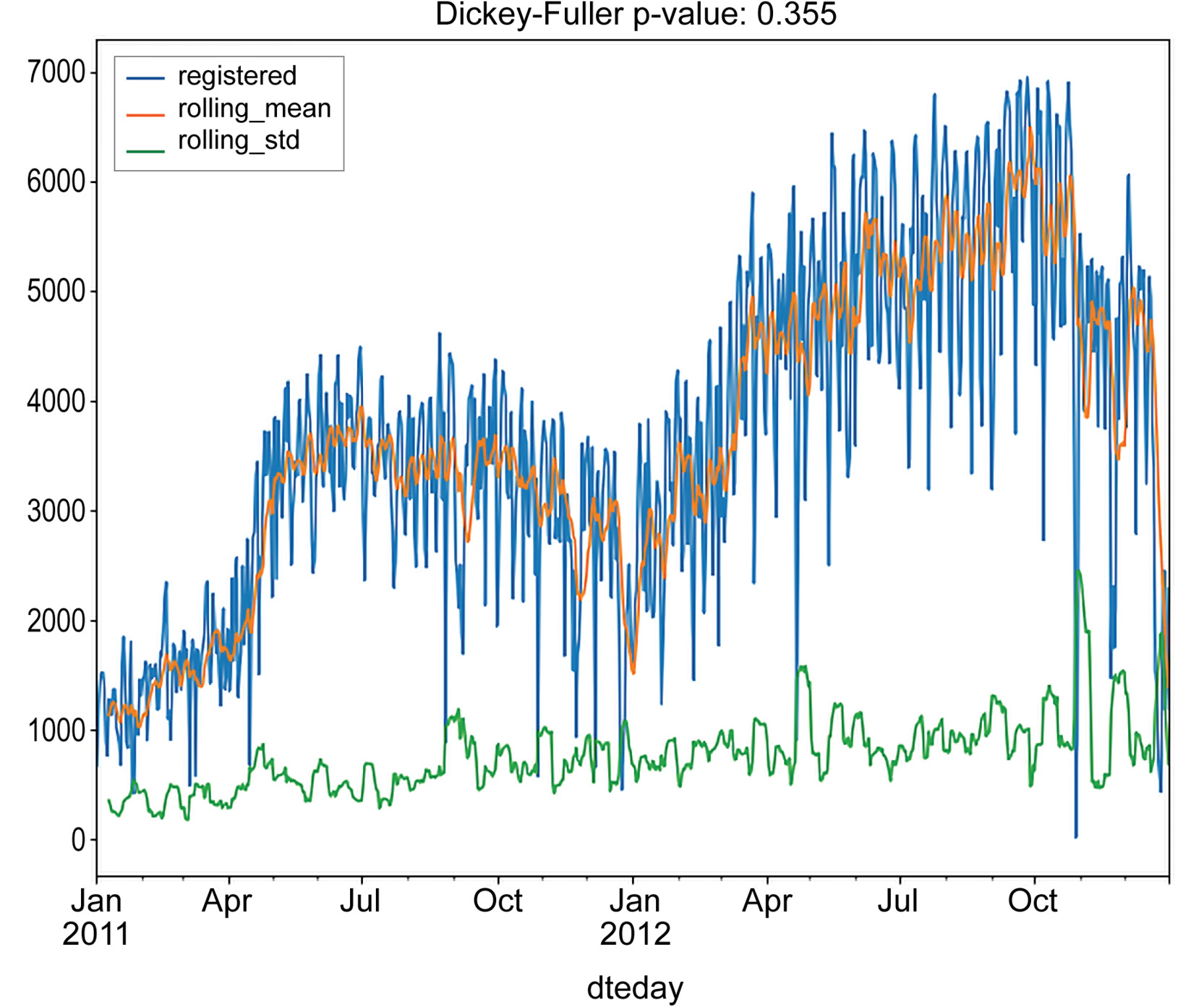
Figure 1.28: Stationarity test results for aggregated daily registered rides
The output for daily casual rides can be as follows:
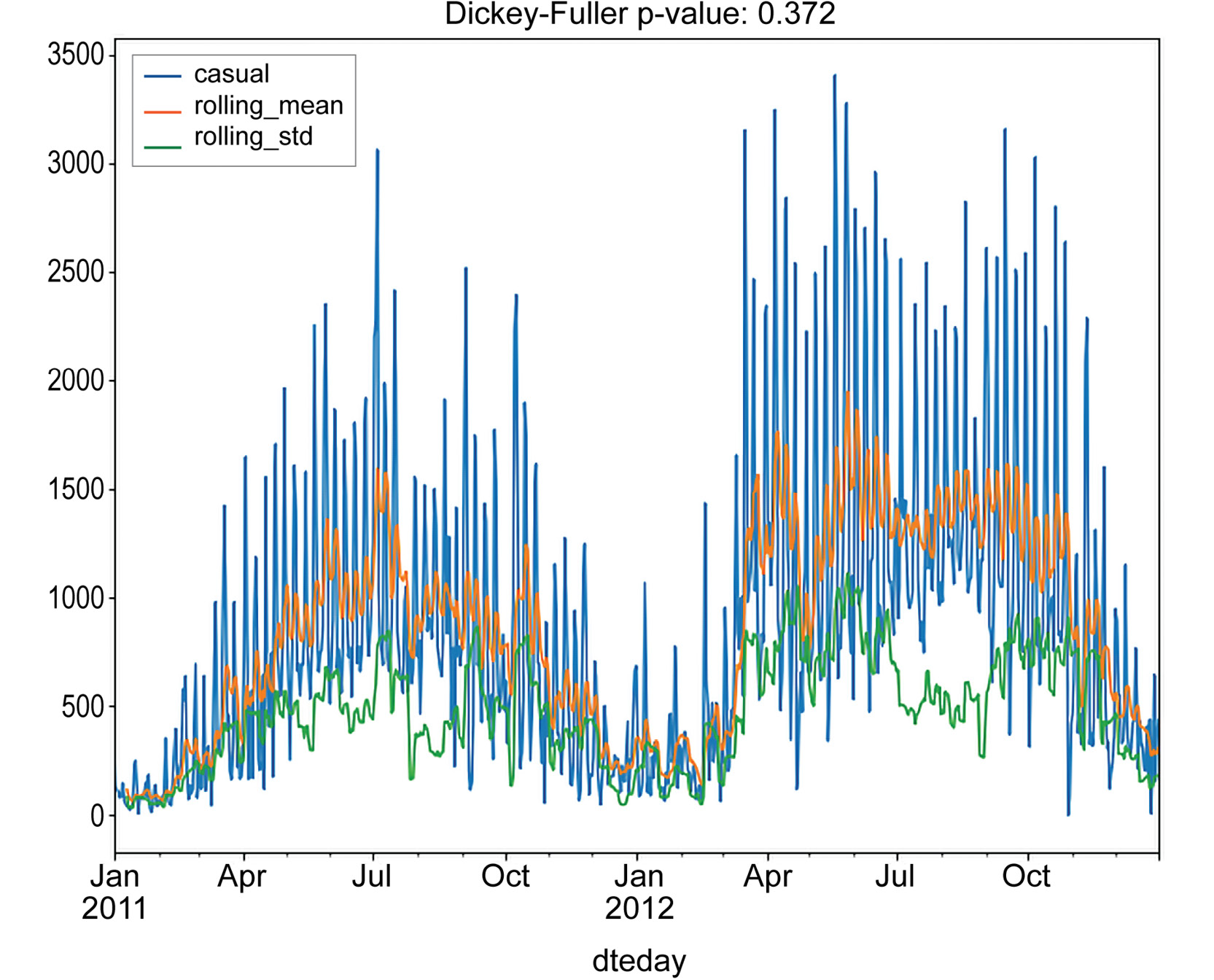
Figure 1.29: Stationarity test results for aggregated daily casual rides
From the performed tests, we can see that neither the moving average nor standard deviations are stationary. Furthermore, the Dickey-Fuller test returns values of 0.355 and 0.372 for the registered and casual columns, respectively. This is strong evidence that the time series is not stationary, and we need to process them in order to obtain a stationary one.
A common way to detrend a time series and make it stationary is to subtract either its rolling mean or its last value, or to decompose it into a component that will contain its trend, seasonality, and residual components. Let's first check whether the time series is stationary by subtracting their rolling means and last values:
# subtract rolling mean registered = daily_rides["registered"] registered_ma = registered.rolling(10).mean() registered_ma_diff = registered - registered_ma registered_ma_diff.dropna(inplace=True) casual = daily_rides["casual"] casual_ma = casual.rolling(10).mean() casual_ma_diff = casual - casual_ma casual_ma_diff.dropna(inplace=True)
The resulting time series are tested for stationarity, and the results are shown in the following figures:
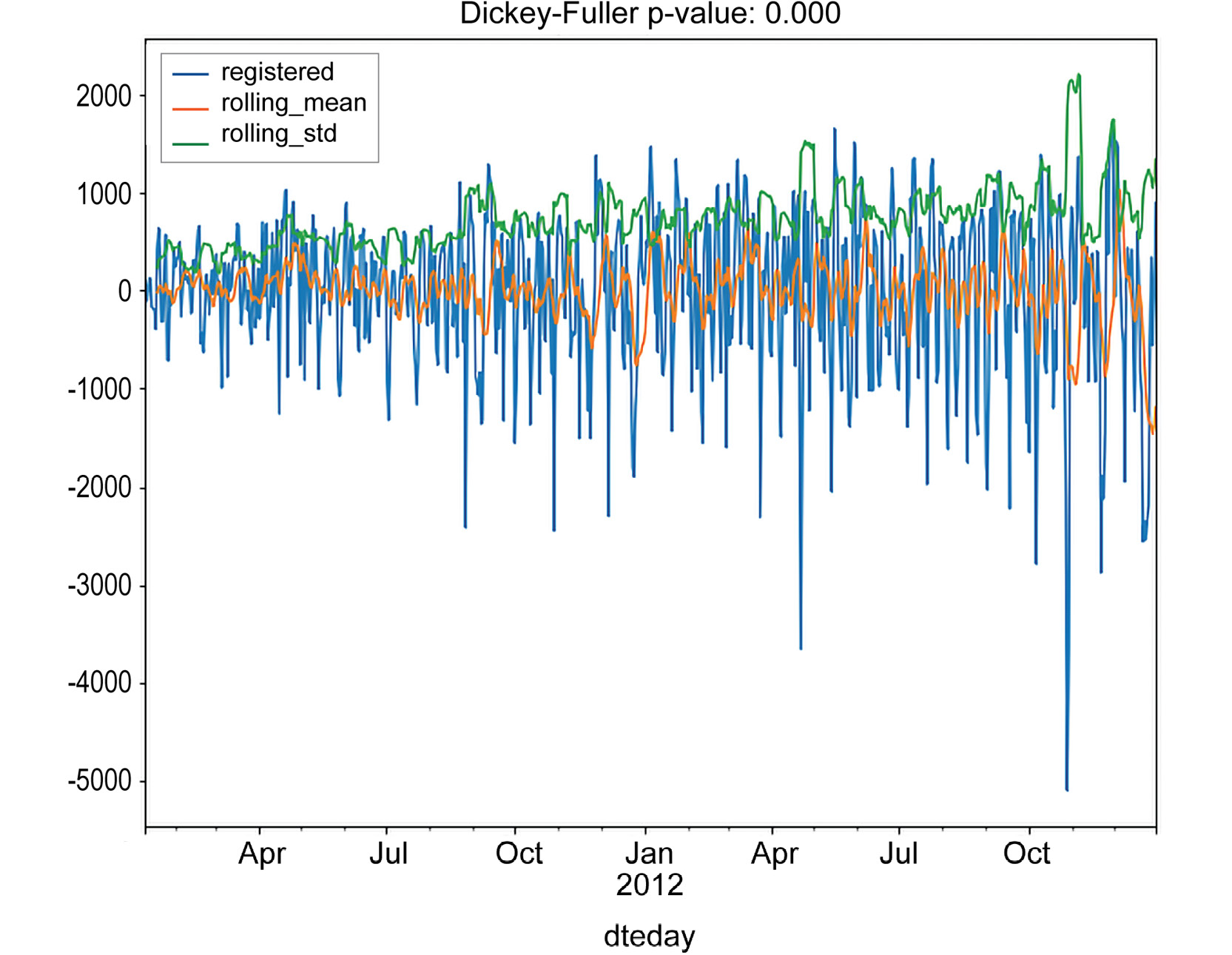
Figure 1.30: Time series tested for stationarity for registered rides
The output for casual rides will be as follows:
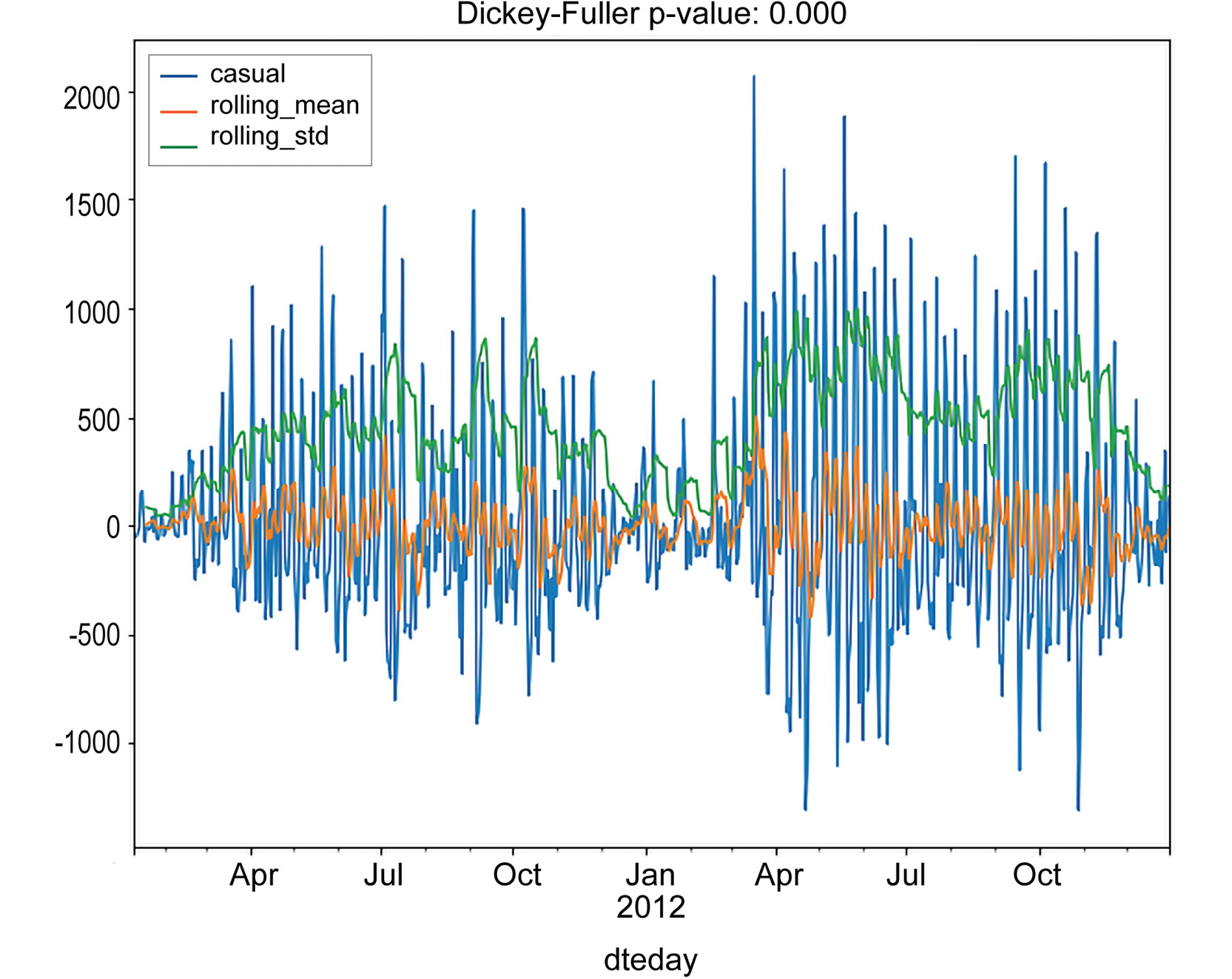
Figure 1.31: Time series tested for stationarity for casual rides
Subtracting the last value can be done in the same way:
# subtract last value
registered = daily_rides["registered"]
registered_diff = registered - registered.shift()
registered_diff.dropna(inplace=True)
casual = daily_rides["casual"]
casual_diff = casual - casual.shift()
casual_diff.dropna(inplace=True)
plt.figure()
test_stationarity(registered_diff, figsize=(10, 8))
plt.savefig('figs/daily_registered_diff.png', format='png')
plt.figure()
test_stationarity(casual_diff, figsize=(10, 8))
plt.savefig('figs/daily_casual_diff.png', format='png')
The output should be as follows:
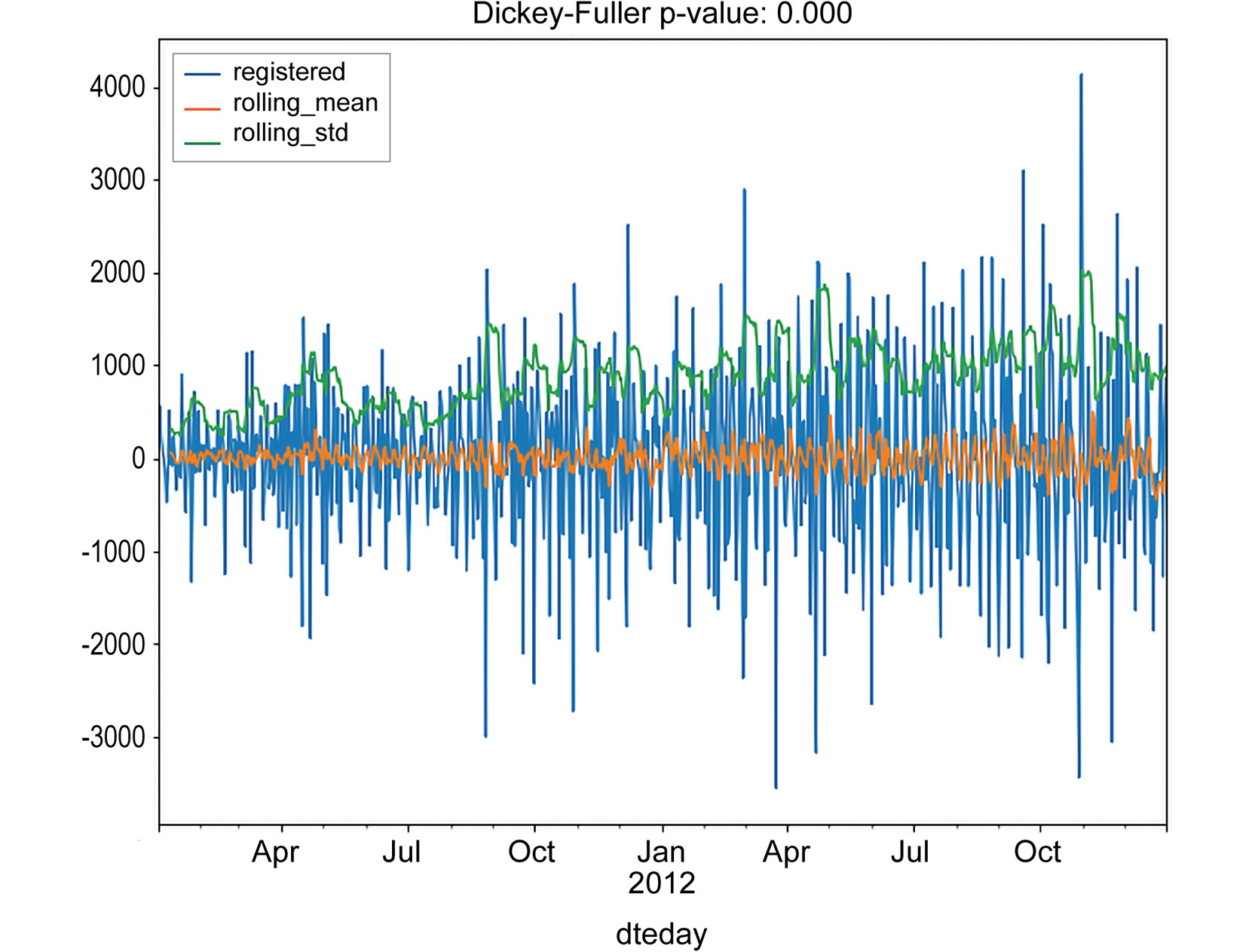
Figure 1.32: Subtracting the last values from the time series for registered rides
The output for casual rides will be as follows:
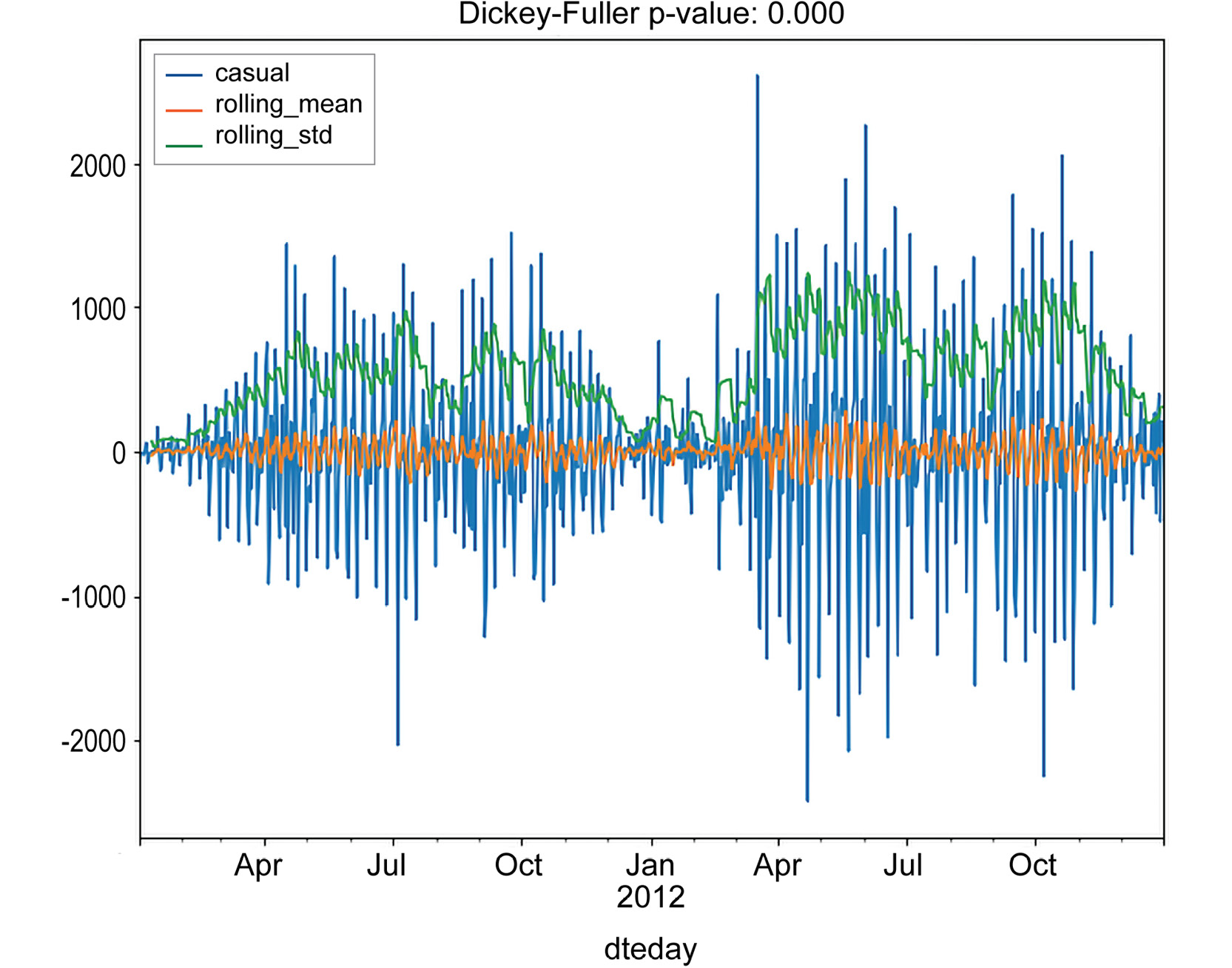
Figure 1.33: Subtracting the last values from the time series for casual rides
As you can see, both of the techniques returned a time series, which is stationary, according to the Dickey-Fuller test. Note that an interesting pattern occurs in the casual series: a rolling standard deviation exhibits a clustering effect, that is, periods in which the standard deviation is higher and periods in which it is lower. This effect is quite common in certain fields (finance, for instance) and is known as volatility clustering. A possible interpretation, relative to our data, is that the number of casual rides increases during summer periods and drops during the winter.
As we saw from the last analysis, removing both the rolling mean and the last value returned a stationary time series. Let's also check also the previously mentioned technique, that is, time series decomposition. This involves breaking the original time series into separate components:
- Trend component: This component represents a long-term progression of the series. A trend component is present when there is a persistent increase or decrease in the series.
- Seasonal component: This component represents seasonality patterns in the data. A seasonal component persists when the data is influenced by certain seasonal factors (for example, monthly, quarterly, or yearly factors).
- Residual component: This component represents an irregular or noisy component. This component describes random fluctuations in the data, which are not captured by the other components. In general, this is the residual of the time series, that is, once the other components have been removed.
A time series decomposition can be framed in the following way. Let's denote, with Yt, the value of the original series at time instance t, and let Tt, St, and Rt represent the trend, seasonal, and residual components, respectively. We will refer to the decomposition as additive if the following holds:
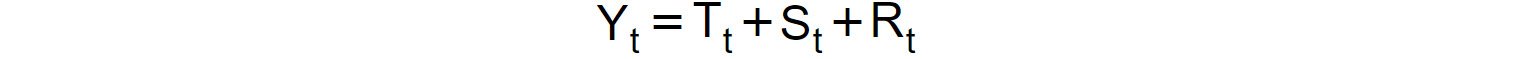
Figure 1.34: Decomposition as additive
And we will refer to the decomposition as multiplicative if the following holds:
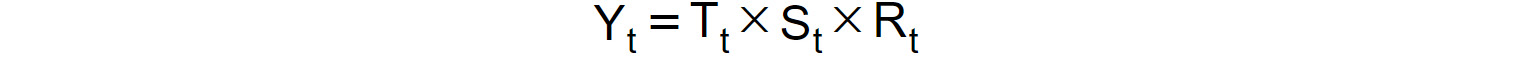
Figure 1.35: Decomposition as multiplicative
In the following exercise, we will illustrate how to perform time series decomposition in Python.
Exercise 1.06: Time Series Decomposition in Trend, Seasonality, and Residual Components
In this exercise, you will exploit seasonal decomposition in the statsmodel Python library in order to decompose the number of rides into three separate components, trend, seasonal, and residual components:
- Use the
statsmodel.tsa.seasonal.seasonal_decompose()method to decompose theregisteredandcasualrides:from statsmodels.tsa.seasonal import seasonal_decompose registered_decomposition = seasonal_decompose(\ daily_rides["registered"]) casual_decomposition = seasonal_decompose(daily_rides["casual"])
- To access each of these three signals, use
.trend,.seasonal, and.residvariables. Furthermore, obtain visual results from the generated decompositions by calling the.plot()method:# plot decompositions registered_plot = registered_decomposition.plot() registered_plot.set_size_inches(10, 8) casual_plot = casual_decomposition.plot() casual_plot.set_size_inches(10, 8) registered_plot.savefig('figs/registered_decomposition.png', \ format='png') casual_plot.savefig('figs/casual_decomposition.png', \ format='png')The output for registered rides is as follows:
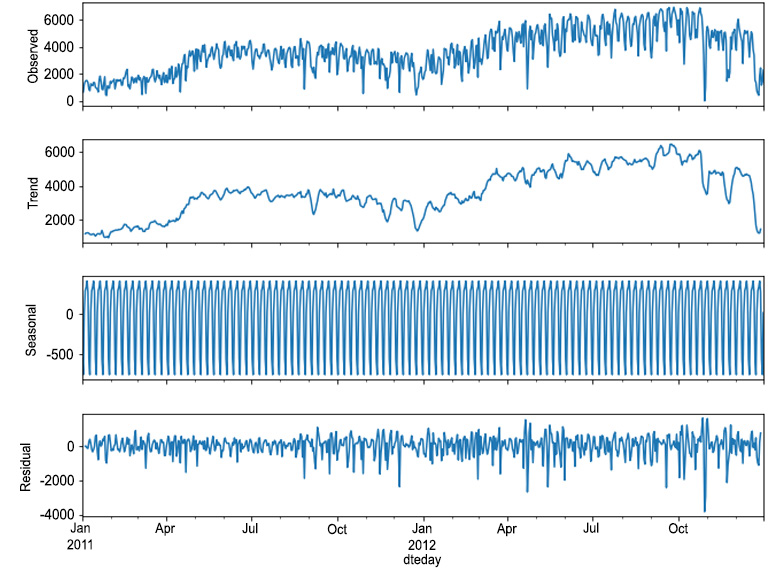
Figure 1.36: Decomposition for registered rides
The output for casual rides will be as follows:
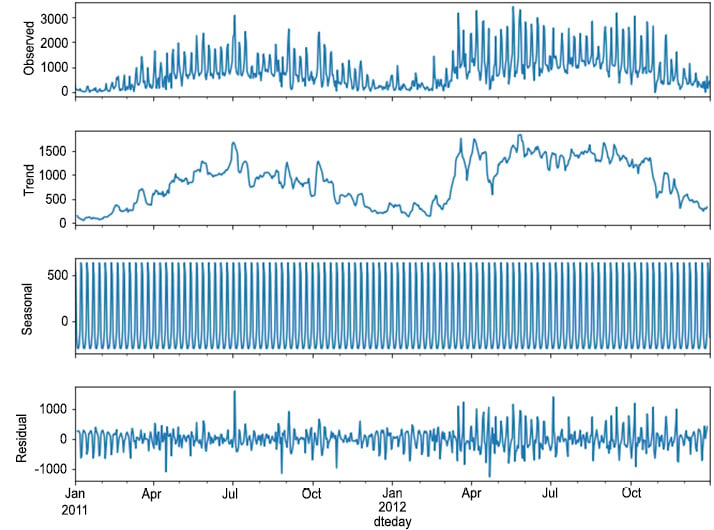
Figure 1.37: Decomposition for casual rides
- Test the residuals obtained for stationarity:
# test residuals for stationarity plt.figure() test_stationarity(registered_decomposition.resid.dropna(), \ figsize=(10, 8)) plt.savefig('figs/registered_resid.png', format='png') plt.figure() test_stationarity(casual_decomposition.resid.dropna(), \ figsize=(10, 8)) plt.savefig('figs/casual_resid.png', format='png')The output will be as follows:
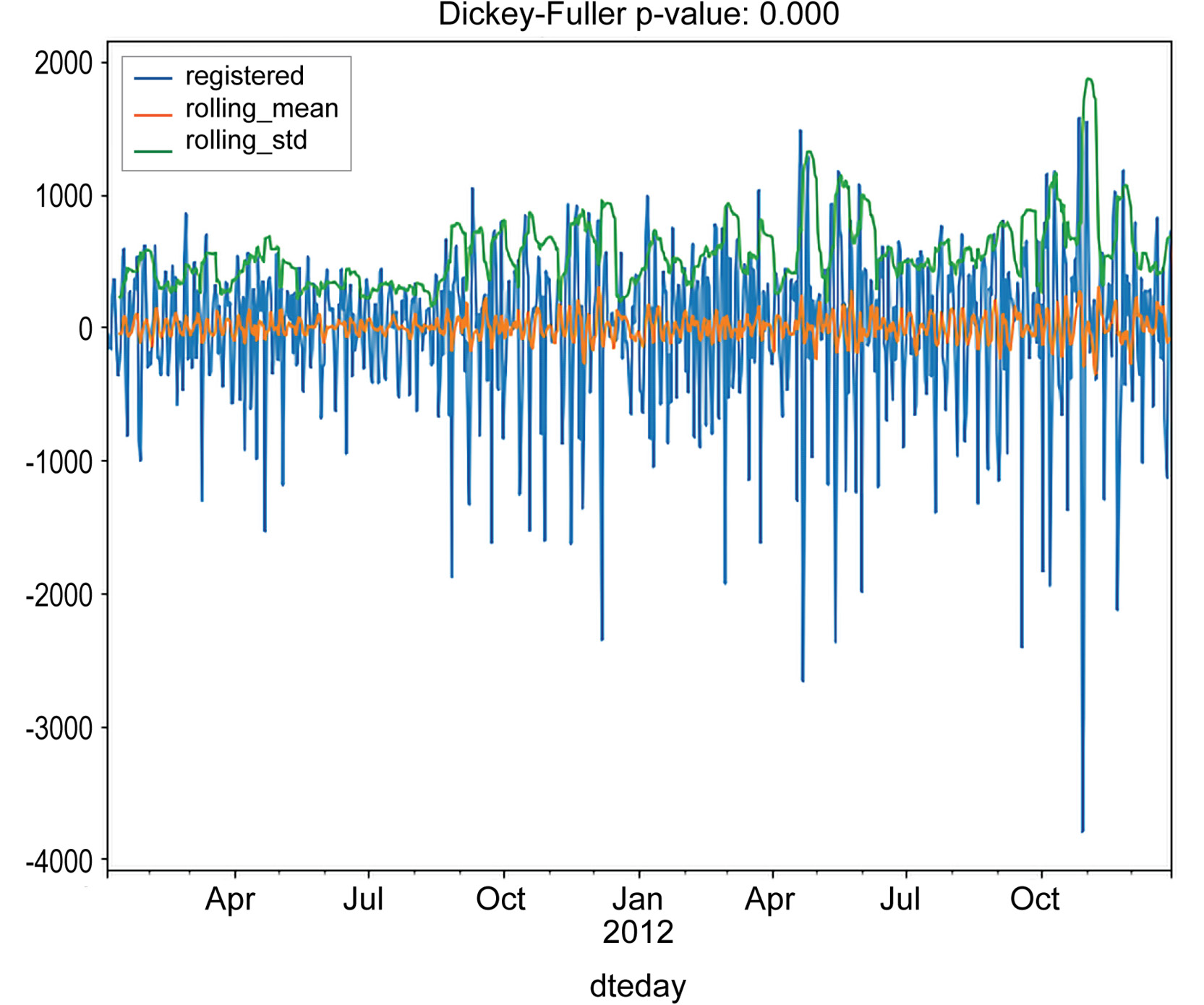
Figure 1.38: Test residuals for stationarity for registered rides
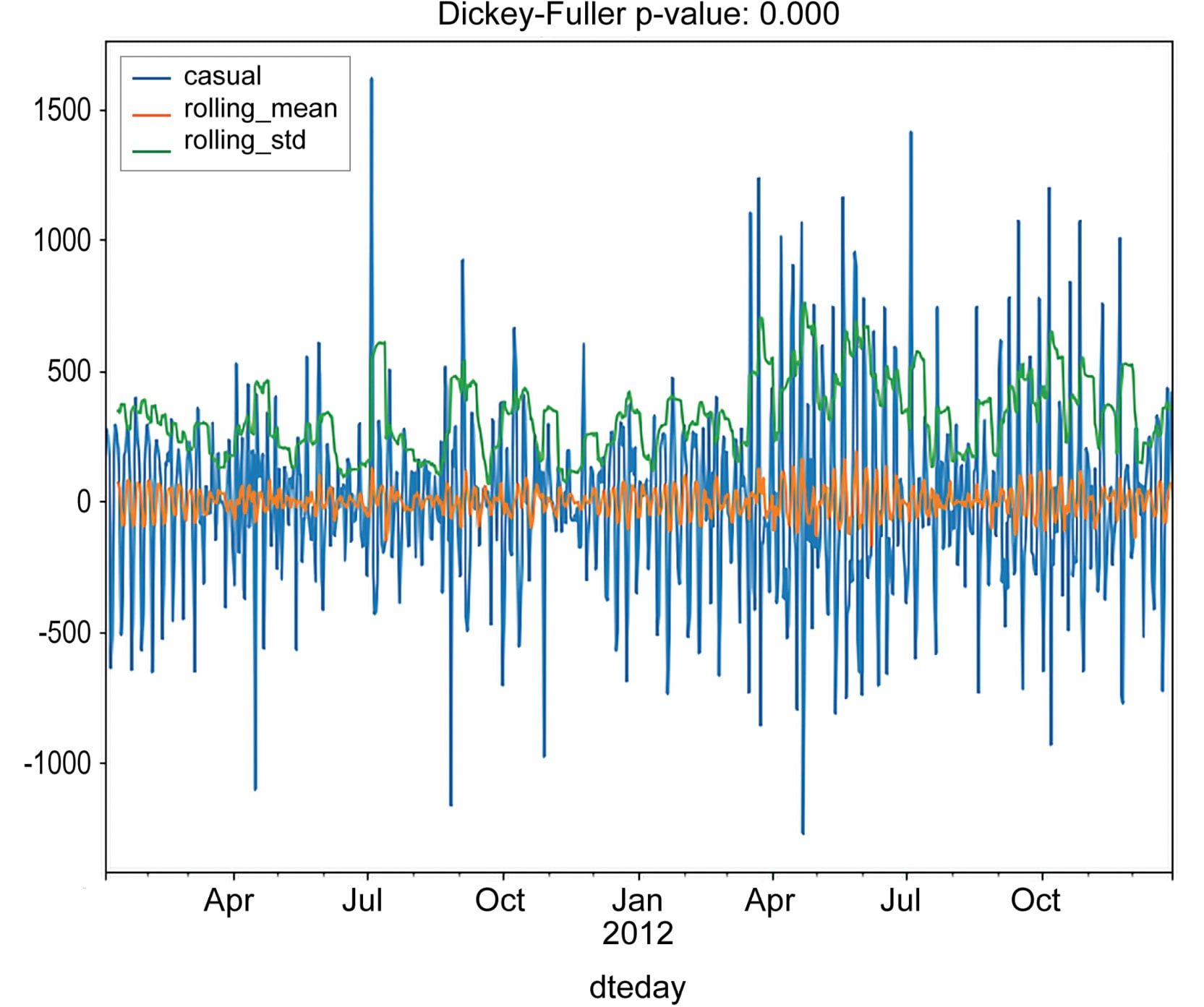
Figure 1.39: Test residuals for stationarity for casual rides
As you can see, the residuals satisfy our stationary test.
Note
To access the source code for this specific section, please refer to https://packt.live/3hB8871.
You can also run this example online at https://packt.live/2BaXsLJ. You must execute the entire Notebook in order to get the desired result.
A common approach to modeling a time series is to assume that past observations somehow influence future ones. For instance, customers who are satisfied by using the bike sharing service will more likely recommend it, producing, in this way, a positive impact on the service and a higher number of customers (obviously, any negative feedback has the opposite effect, reducing the number of customers). Hence, increasing the number of customers and the quality of the service increases the number of recommendations and, therefore, the number of new customers. In this way, a positive feedback loop is created, in which the current number of rides correlates with its past values. These types of phenomena are the topic of the next section.




