






















































History of presentational patterns
In this section we will cover the history of presentational (or GUI) patterns. Presentational patterns have been around for over 30 years and a full coverage of all the various patterns is outside of the scope of this book. We will instead focus on two of the major trends that have emerged over the last 30 years and look at how those two trends eventually evolved to MVVM for Silverlight and WPF.
Note
If you are interested in learning more about the history of presentational patterns than what is covered here, then see Martin Fowler's article GUI Architectures (http://martinfowler.com/eaaDev/uiArchs.html).
Monolithic design
Enterprise applications deal with displaying, manipulating, and saving data. If we build enterprise applications with no design so that each GUI component is coupled all the way down to the data access code, then there are a lot of problems that can emerge.
This style of design is called monolithic and the following diagram shows the coupling that exists under monolithic designs:

The problems with monolithic design
In this section we will review the problems caused by the tight coupling and low cohesion found in monolithic designs.
Code maintenance
Looking at the previous screenshot if you assume that UI Widget1 and UI Widgetn are using the same business logic, then using a monolithic design will cause code duplication. Every time a change needs to be made to the business logic, it would need to be made in both places. This is the type of issue that is solved by SoC and one of the motivators for design paradigms like 3-tier which we will look at in the Layered design section later in this chapter.
Code structure
Not having the code structured into reusable components and well-organized layers makes things like sharing session state difficult under monolithic design. As you will see in the examples that follow, once we move to MVC and MVP, there are many benefits including:
The session state becomes much easier to manage and share
Code is easier to reuse
Code is well-organized and easier to understand and maintain
Code scales easier as you can build components into separate DLLs for distributed deployment
Code is more extensible as you can replace components to provide different behaviors
Code testability
Creating code that can be effectively tested with unit tests requires designing for testability. The monolithic approach poses several problems for code testability including:
Poor isolation of tests: One of the core principles of unit testing is isolation of the tests. You want your unit tests to test one scenario of one method of one class and not to test the dependencies. Following this principle makes your tests more valuable because when a test fails it's more likely that developers who didn't write the test but introduced the change that broke the test will fix the issue. This is because it will be very easy for the developer to determine what the problem was that broke the test because it's so isolated and clear in its purpose. A big part of getting return on investment from unit tests comes from making them easy for developers to use and avoid making your unit tests high maintenance. With high-maintenance unit tests the developers might just delete, disable, or comment out the test instead of fixing the problem, which makes the expense that was put into creating the test a waste.
Testing the UI is difficult: Using automated testing to test the UI is notoriously difficult. Monolithic design makes this problem worse as there is no separation between the UI and the rest of the layers of logic. One of the major contributors to the need of separated UI patterns is the desire to move as much logic as possible out of the UI and into separate testable components.
Poor code coverage: Code coverage refers to how much of your code is covered by unit tests. Generally speaking, the more code you have covered by tests, the more stability you will create in your development process, and the more benefits you will reap from your tests. High code coverage provides fewer bugs and quicker refactoring times. When you create a monolithic application, it affects your ability to achieve high code coverage levels, because you can't test the UI logic and the coupling between the various layers as it makes mocking dependencies difficult, prohibiting creation of unit tests.
Note
100 percent test coverage is not always the best level of coverage as too much coverage can make the code brittle to change and make the code high maintenance. My general rule of thumb is that I want to test the functionality that is defined by the public interface of the class under test. Testing internal details that could change can provide more inconvenience than benefit. However, this rule of thumb assumes that you have a good separation of concerns and have applied the Single Responsibility Principle to the design of your application. Single Responsibility Principle is part of the SOLID design principles and more details about SOLID are easily found online if needed.
Data service stub
We will be using a data service stub as part of our data layer to take the place of a real data service in our sample applications so that we can focus on presentation patterns and not on data access patterns and techniques.
Note
Data layer will be explained in the Layered design section later in this chapter.
Let's start by creating a new Class Library project called ProjectBilling.DataAccess in a solution called MVVM Survival Guide as shown in following screenshot:
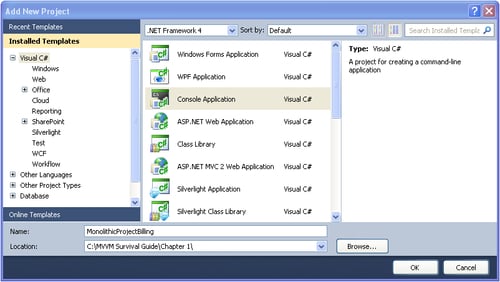
Now delete the Class1.cs file that is created by default by the project template and add a new class called Project and add the following code to Project.cs:
namespace ProjectBilling.DataAccess
{
public interface IProject
{
int ID { get; set; }
string Name { get; set; }
double Estimate { get; set; }
double Actual { get; set; }
void Update(IProject project);
}
public class Project : IProject
{
public int ID { get; set; }
public string Name { get; set; }
public double Estimate { get; set; }
public double Actual { get; set; }
public void Update(IProject project)
{
Name = project.Name;
Estimate = project.Estimate;
Actual = project.Actual;
}
}
}Note
There are certainly better options than using an interface with an update method to allow for updating data objects but this approach will allow us to keep the code in this chapter and the next concise and allow keep our focus on the topic at hand.
Project is a simple domain object (or business object) that stores the project name, estimated cost, and actual cost. It's implemented off an interface to provide more flexibility and better testability and it provides an update method to make it easy to update an instance's values.
Now we will create the data service stub that will return fake data for our various clients to consume so that we don't have to be concerned with data access patterns and techniques and can instead focus on presentation patterns. Add a class to the project called DataService and add the code that follows to DataService.cs.
This class exposes one method called GetProjects(), which creates three projects and then returns them as a IList<Project>. We have implemented our data service stub based on an interface to support
dependency injection.
Note
Dependency injection is a pattern where a dependency is allowed to be specified by an external component instead of being created internally. This pattern will be covered in more detail in Chapter 6, Northwind—Hierarchical View Model and IoC.
using System.Collections.Generic;
namespace ProjectBilling.DataAccess
{
public interface IDataService
{
IList<Project> GetProjects();
}
public class DataServiceStub : IDataService
{
public IList<Project> GetProjects()
{
List<Project> projects = new List<Project>()
{
new Project()
{
ID = 0,
Name = "Halloway",
Estimate = 500
},
new Project()
{
ID = 1,
Name = "Jones",
Estimate = 1500
},
new Project()
{
ID = 2,
Name = "Smith",
Estimate = 2000
}
};
return projects;
}
}
}Tip
Downloading the example code
You can download the example code files for all Packt books you have purchased from your account at http://www.PacktPub.com . If you purchased this book elsewhere, you can visit http://www.PacktPub.com/support and register to have the files e-mailed directly to you.
This will allow us the flexibility to provide different implementations depending on the context. In a unit test we can provide a testing fake (stub or mock), in blend we can return a stub that returns design-time data and at runtime we can provide a real data service that returns real data. We will look into all of these techniques and also the use of inversion of control frameworks that make this process easier later in this book.


