























































Introducing the Domo ecosystem
The Domo ecosystem was designed from its inception to be disruptive to how data is acquired, structured, stored, transformed, shared, used, extended, and governed. The overarching objective in its creation was to empower everyone to answer business questions at the speed of business. For example, no more waiting in the proverbial BI breadline for IT or technical resources. Understanding that many questions have a shelf life and are perishable in their utility is a foundational belief that translated into access, speed, and agility in the product. A large part of the product investment was made in data acquisition/pipeline capabilities to ensure that the most difficult and time-consuming activities in answering business questions, namely data intake, storage, and sculpting, are streamlined for the non-technical user while preserving appropriate security.
Therefore, to answer questions quickly, it follows that a typical user needs to be able to do the following:
- Intake data quickly, whatever the data volume, variety, and velocity.
- Provide data extraction to outtake data from Domo to other applications.
- Have the data automatically stored and indexed for fast queries at scale.
- Sculpt the data and automate data pipelines.
- Present relevant stories that drive favorable outcomes.
- Securely share information and communicate with context.
- Enable extensions with a crowd-sourced app store and custom apps.
This unique combination of pre-integrated and universally governed layers in the ecosystem enables non-technical users to quickly, accurately, securely, and relevantly deliver end-to-end solutions.
The following diagram visualizes the Domo ecosystem:
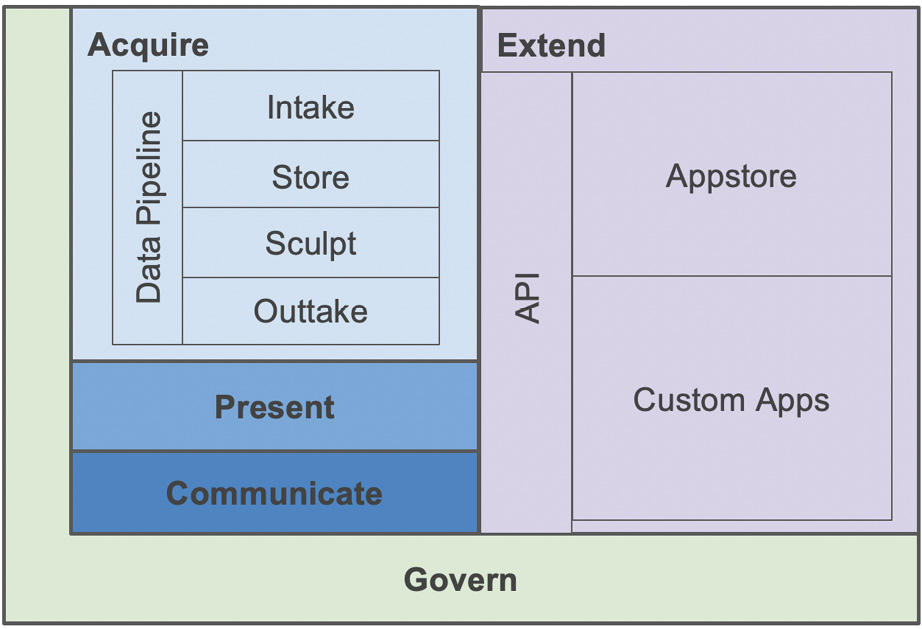
Figure 1.1 – The Domo ecosystem
Let's look at each of the layers shown in Figure 1.1 in turn, starting with Acquire.










